对富 Js 网站的一点思考
0x00 前言
最近刚刚用docsify重建了blog,docsify是由js驱动的,这样的网站一般称之为JavaScript-rich,我一般将其翻译为富js网站。在重构的过程中产生了一点思考,也是这类富js网站的缺陷,记录如下。
0x01 对CDN不友好
CDN溯源只会简单地回溯源站内容,也就是说,只会回溯网站源代码并缓存,而对于使用js驱动的网站来说,网站源代码往往就只有一份,就像我现在的这个blog网站一样,所有的网页内容全部是通过js渲染上的,CDN溯源只会在CDN结点缓存上网页源代码,CDN结点是不会执行js代码来获取网页实际内容的,这就导致了CDN无法依据实际的URL缓存网站内容。
这点我问了腾讯云的CDN工程师:
0x02 对SEO不友好
目前绝大多数搜索引擎的爬虫们还只会爬取网页源代码,对于客户端使用js渲染后的内容,他们一无所知。这就导致了对SEO不友好,网站搜索引擎权重下降,用户使用搜索引擎来导向到你的网站的难度就愈发增加,而对于大多数个人网站而言,搜索引擎往往是网站访客的主要来源,一下子把这个主要来源给架空了,着实让我有点难受。
在这一方面我查了一些资料,大家可以参考一下:
Going Beyond Google: Are Search Engines Ready for JavaScript Crawling & Indexing?
Understand rendering on Google Search
Can Google Properly Crawl and Index JavaScript Frameworks? A JavaScript SEO Experiment.
JavaScript SEO – How Does Google Crawl JavaScript
phantomJS+nodeJS+nginx完美解决前后端分离SEO问题
简要概括一下这几篇文章内容,如下:
我们在这仅讨论js的Client-Side-Rendering(客户端内容渲染),也就是用户访问网页之后,返回一份网页源代码,网页源代码中包含一段js代码用来从服务端进一步获取内容,然后使用js动态将内容渲染至网页。像docsify这样的静态网页框架,多半就是基于客户端内容渲染的,网页源代码里啥也没有,不含有涉及网页内容的任何信息,例如本网站。
首先只有极少数搜索引擎是会将网页中的JavaScript内容渲染出来然后再爬取一遍,获得渲染后的内容的,他们测试了全球知名的几大搜索引擎对使用不同JavaScript框架渲染后内容的爬取程度,如图:
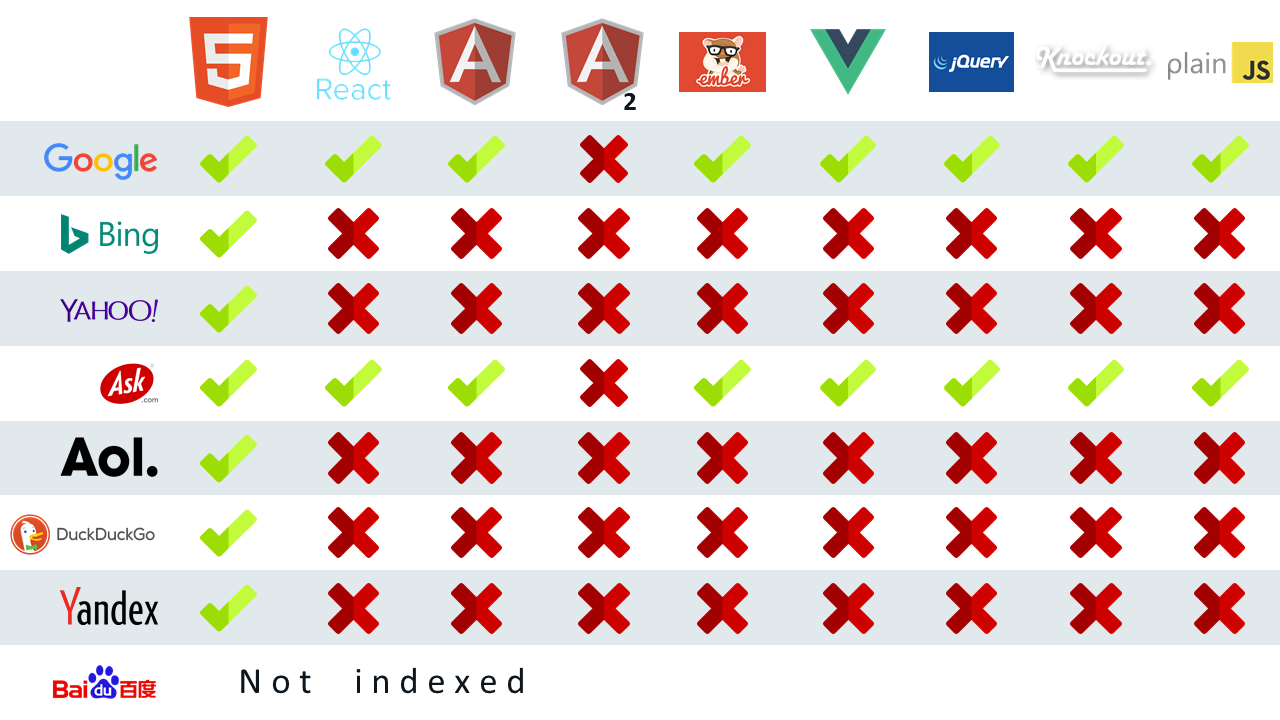
从图中我们可以看出,Google和Ask是对使用js渲染过后的网站支持最好的,两者均可以支持常见的js开发框架。其他搜索引擎仅会简单地爬取网页源代码,并不会执行JavaScript得到渲染后的内容。
因为百度对外国人太不友好,他们已经尽了最大的努力,试图让百度收录他们的测试网址,但是他们还是失败了,主要原因在于:
百度需要一个中国大陆的手机号才能注册,这一点挡住了绝大多数国外的webmaster
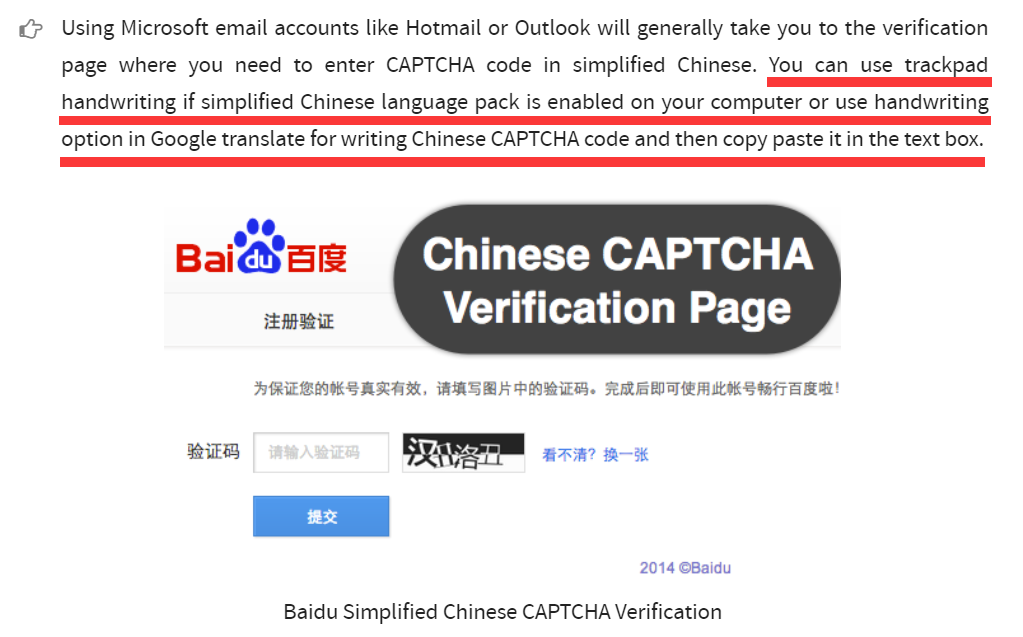
百度的注册验证界面使用的是中文验证码,这就说明,这百度啊,他是从来都没有想过让外国人用啊
看到没有,中文验证码,外国人看到这个就彻底蒙了,他们提出了一种解决方案,就是首先你的电脑得安装了中文语言包,然后去买一个手写板,在手写板上比这验证码里面的中文画一个,然后再使用谷歌翻译的照片翻译功能将你画的那个中文验证码识别成文字的形式,然后再复制到那个验证码框里,可是又有多少外国人电脑里面安装了中文语言包,又又有多少外国人有手写板呢。
综上原因,我们在这里也不讨论百度
同时,Ask是基于Google的,也就是说目前只有Google一家在做对客户端渲染的js内容进行渲染爬取,其他搜索引擎的爬虫均不会渲染客户端的js,这主要得益于Google的Caffeine引擎,如图:
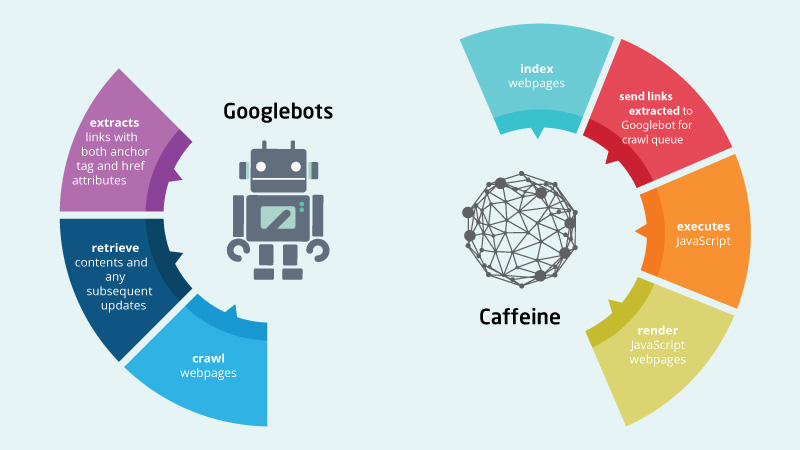
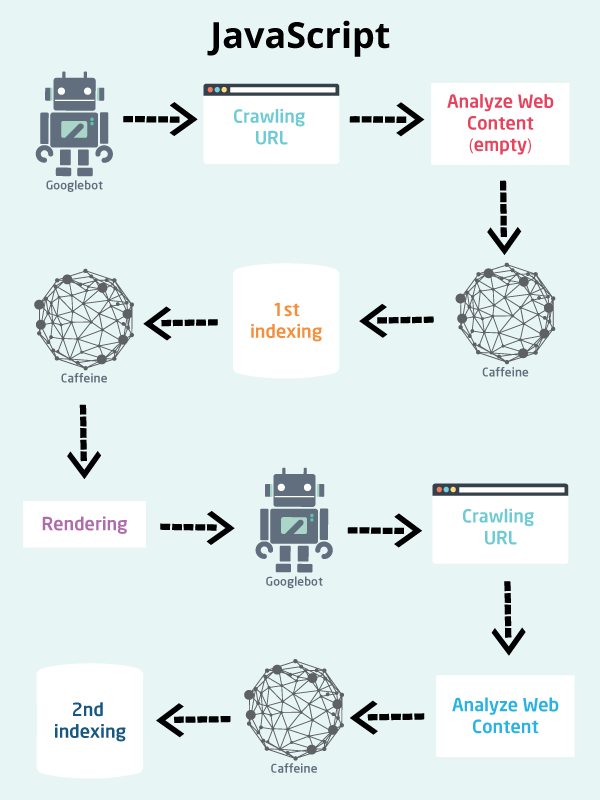
由上图可知,Google的爬虫从网站上爬取源代码后,交由Caffeine引擎进行第一步索引,之后Caffeine引擎对网页进行渲染,然后将渲染后的页面再次交由爬虫爬取,然后将返回的内容进行二次索引,以索引网页上由js渲染的动态内容。
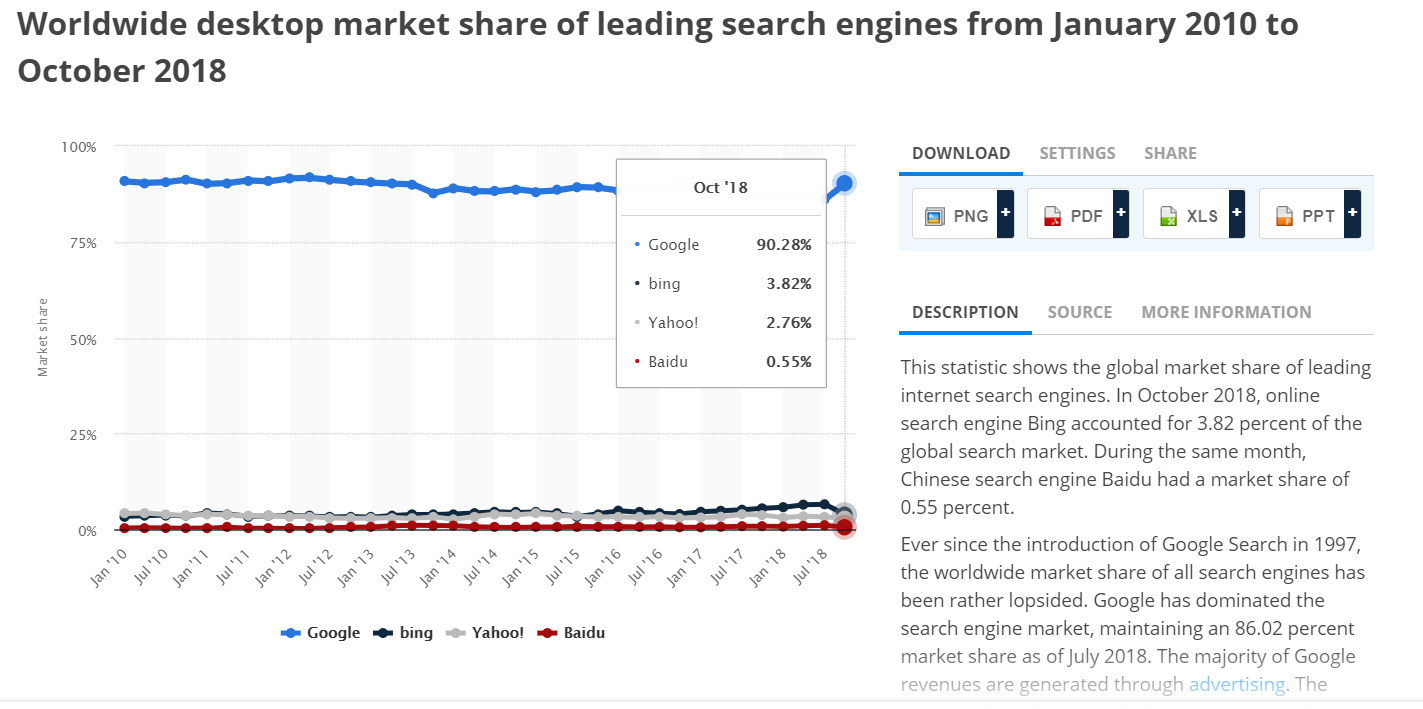
Google可以对网页进行JavaScript渲染,然后索引渲染后的内容,依据statista的统计数据(如下图),在全球范围内(不是全中国),Google的市场份额在90%上下,从这一角度分析,你的网站在全球范围内从搜索引擎中流失的用户数量在10%左右。当然如果你是中文的网站,内容主要面向中国,这个数字会被放大,真正流失的用户可能会更多,初步估算可能会高达95%以上,毕竟Google已经退出中国。
Google的Caffeine引擎在进行js渲染时使用的是Chrome 41的引擎,你没看错就是Chrome 41,截止2019年,现在都出到Chrome 71了,它仍然使用的是过时已久的浏览器引擎,这点我们可以从Google的官方文档中找到答案Understand rendering on Google Search,因为众所周知的网络原因,很多国内用户无法访问上面的链接,所以,我对其做了截图:

Caffeine引擎对部分js文件的执行和渲染的行为做了修改,屏蔽了一些js的接口和功能,主要涉及:
- IndexedDB和WebSQL的接口全部被屏蔽
- 在这个网页Service Worker specification里列出的所有接口均被屏蔽
- WebGL相关方法被屏蔽
- 3D和VR渲染所得内容不会被执行和索引
Caffeine进行渲染索引的整个过程都是无状态的,这意味着:
- Local Storage、Session Storage和HTTP Cookies的内容会在此页渲染完成之后被清空
同时,因为使用的是Chrome 41的内核,ES6的相关特性均不会被支持,而且Caffeine引擎不支持WebSocket,仅支持HTTP/1.x和FTP,不支持TLS(安全传输层协议),现在的网站,基本上是个HTTPS都是基于TLS进行传输的,这点你可以在浏览器F12的security页里看到,就比如说我的网站:
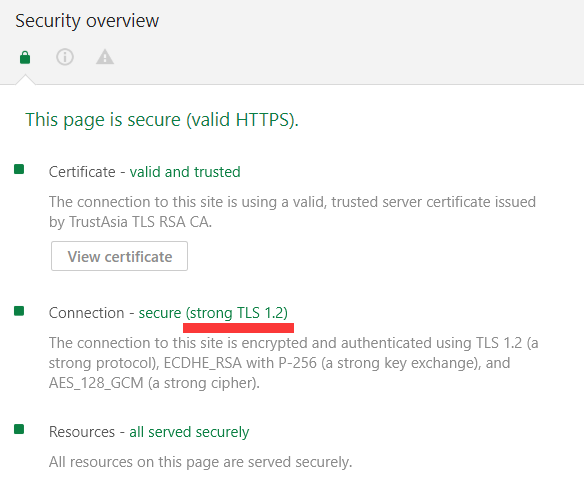
如果你在security页面里也看到了这个TLS,恭喜,你的网站,不会被Caffeine引擎进行客户端js渲染。
怎么样,这就基本上算是断了我们这些小博客网站从搜索引擎中获得流量的出路。
当然也有解决的办法,第一种就是做Server-side rendering,服务端渲染,这在docsify里有一个现成的解决方案:Server-Side Rendering。
第二种就是,在搜索引擎和网站之间建立一个中间站,使用nginx进行分流,当检测到来访流量的User-Agent字段中含有Googlebot等搜索引擎爬虫字样的UA就将其引流至中间站,在中间站存放着渲染好的网页内容副本。这样就可以让爬虫直接在网页源代码里爬到相关网页内容(也就是第一次索引时)。这种思路可以参考文章:phantomJS+nodeJS+nginx完美解决前后端分离SEO问题。
 支付宝
支付宝- 微信


