分布式
0x00 CAP 理论
经济学中有一个著名的论断叫蒙代尔不可能三角,说货币政策的独立性、汇率的稳定性以及资本自由流动,三者不能都要,最多只能实现其中两个。分布式系统中也有一个类似的CAP理论(CAP theorem),说数据的一致性、系统的可用性以及允许分区,三者不能都要,最多只能实现其中两个。
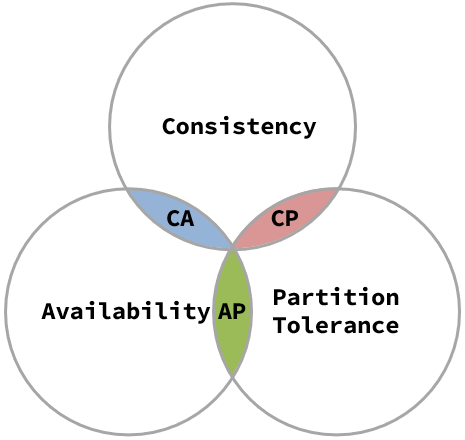
- 数据的(强)一致性(Consistency):表示数据的更新操作在所有节点间都像原子操作一样,要么同时成功要么同时失败,不会出现部分成功的状况。以数据库为例,则是主从库之间的同步不会出现一个中间状态,主库更新了,但从库没有更新,继而导致查询从库与主库结果不符的现象。
- 系统的可用性(Availability):表示集群的服务一直处于可用状态,可用状态的要求则是在有限的时间内返回正确的结果。即便部分节点挂了,其它存活的节点也能正常返回数据,哪怕会有不一致的情况发生。
- 允许分区(Partition Tolerance):分区是指因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区。如下图所示的情况,node02为主库,剩下的两个为从库,node02和node03之间的主从同步断了之后,即形成了以不同底色区分的两个分区。
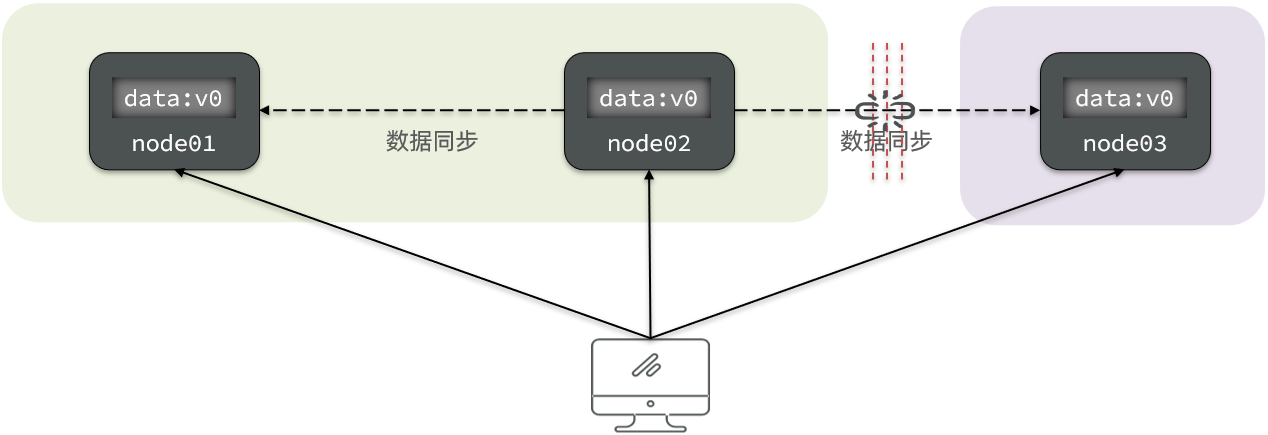
对于分布式系统而言,系统间的网络不能保证100%的健康,一定会有故障的时候,也就是说分区一定会出现。当出现分区后,如果要保证数据一致性的话,就必需等待网络恢复,完成分区间的数据同步之后,整个集群才能对外提供服务,就不能保证可用性。如果要保证可用性,就必需放弃一致性,即便两个分区内的数据不一致,也要同时对外提供服务。也就是说在P一定会出现的情况下,A和C只能实现其中一个。
依据A和C所放弃的选项不同,可以分为AP和CP两种不同的分布式系统,分别适用于不同的场景:
- AP,可用性优先:适用于绝大多数互联网场景,对数据一致性没有那么强的诉求,或只需要保证最终一致性即可。就比如我发了一条微博,可能北方的网友刷新一下我的个人主页能立马看到,而南方的网友则需要等几秒刷新才能看到。可能会出现一个数据不一致的中间态影响用户体验,但只要最终的结果是大家都能看到就行。
- CP,数据一致性优先:适用于需要强一致性保障的场景。考虑一个银行的场景,一个分布式数据库中存放着所有用户的账户余额。如果主从库之间数据同步链路断掉,发生分区。小明的账户上有10块钱,我们肯定不希望这次请求访问的主库扣掉了10块,但是从库没扣,下次请求访问到了从库发现余额还有10块,还能继续消费。所以在这种场景下,就必需放弃可用性。当主从之间的同步链路断了之后,要么下掉从库确保所有的读写操作都在主库或者都在同一分区,要么就暂停服务等待网络恢复。
0x00 BASE 理论
如上文所述,在设计分布式系统时,需要在可用性C和一致性A之间作出抉择,总要放弃一个。BASE理论则是二者的一个权衡方案, 是在AC之间的一个妥协和折中。基本思路如下:
基本可用(Basically Available, BA),是相对CAP的“完全可用”而言的,即在部分节点出现故障的时候不要求整个系统完全可用,允许系统出现部分功能和性能上的损失:比如增加响应时间,引导用户到一个降级提示页面等等。
软状态(Soft State,S),CAP理论的C代表强一致性,要求数据变化要立即反映到所有副本节点上,不会有一个中间态主库更新了从库没有更新(主从延迟)。软状态则是允许有主从延迟的中间态。
最终一致性(Eventually Consistency,E),不要求节点间的数据始终保持一致性,只要最终能达到一致性状态即可。
0x01 案例学习——以数据库为例
0x00 CP数据库 —— MongoDB
CP即数据一致性优先,分布式部署的MongoDB会包含一个主库和多个从库。所有的写操作都在主库进行,而读操作可以在主库和从库之间进行。从库挂了无所谓,因为没有写操作,故不影响整体的数据一致性。而单一主库一旦挂了,MongoDB就会在剩余的从库中再选出一个主库来,并且其它存活的从库会与新的主库完成一次数据同步,以确保数据的一致性。在选主以及一致性同步完成之前,整个集群是不可用的。
0x01 AP数据库 —— Apache Cassandra
Apache Cassandra为了保证强可用性,采用了无主模式(masterless),整个集群没有主库,所有节点都是平等的,读写操作可以在所有节点之间完成,通过一定的策略来保障数据的最终一致性。
首先,假设一个Cassandra集群有N个节点,那我们会设置一个复制系数(Replication Factor, RF)M。集群中的节点会随机选M个节点进行配对,作为对方的副本节点。当进行数据的写入操作时,会同时向这M个节点写入数据。
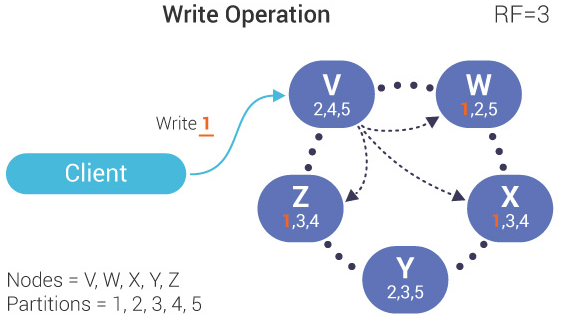
如果一个节点写入失败,则将这条写入消息保存到其副本节点的hint表中。当副本节点通过Gossip机制发现其所存储hint数据的所属节点恢复正常后,再回放hint表中保存的曾经失败的写入请求。确保在这M个节点内,数据是一致的。
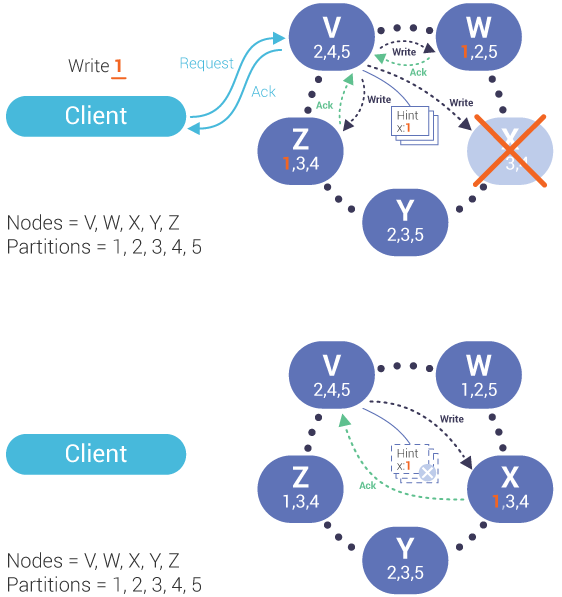
如上机制即被称作提示移交机制(Hinted Handoff),主要用于保障写操作的可用性,不管集群中是否有节点失败,只要还有一个存活的节点,就永远都可以写入。
当从集群中读取数据时,则一次从这集群中M个节点中读取数据。如果这M个节点内保存的数据都一致的话,那么就直接返回。如果这M个节点返回的数据出现不一致的情况,则依据时间戳排序返回最新的结果。同时发现不一致的情况后会刷新这M个节点,确保在这几个节点内的数据是一致的。
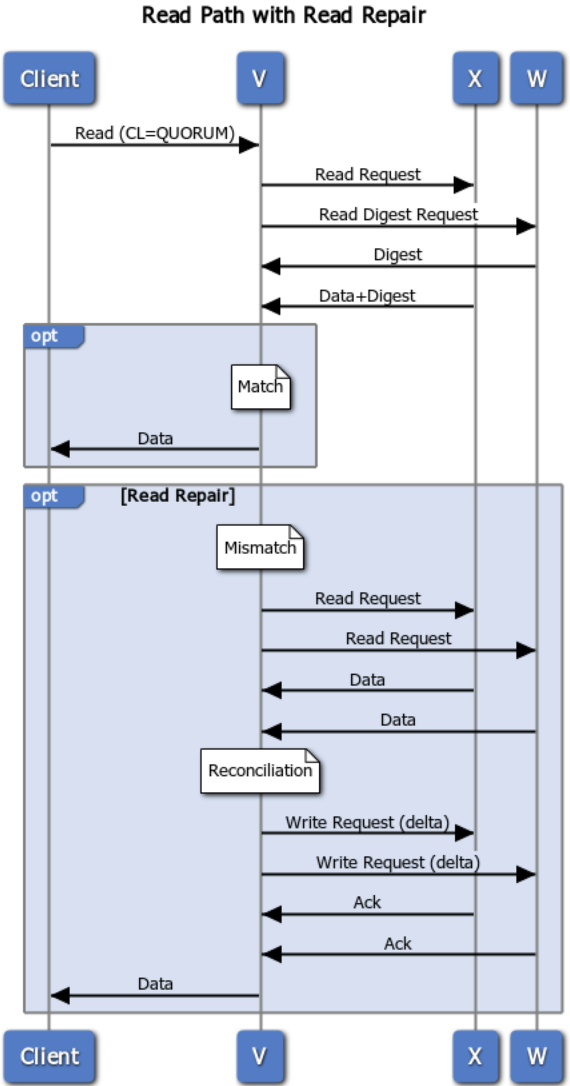
这一机制即被称作读修复(Read Repair)。在这个过程中,M的值越接近N,对数据一致性的保障程度就越高,同时也允许集群中的越多节点挂掉后仍能正常读到数据,但与之付出的代价则是每次读取成本的升高。
当进行数据删除时,如果发生分区,就难免会遇到某些节点删除成功了,某些节点删除失败的情况。这样下次请求再访问到删除失败的节点上时就会读到已经删除的数据。为此,Cassandra引入了分布式删除机制,在数据删除后,会在已经删除的节点上立一个墓碑(tombstone)。下次读取时,如果有一个节点返回了它的墓碑,则表示当前数据已经删除,即便有节点删除失败返回有数据,但依然返回为空。
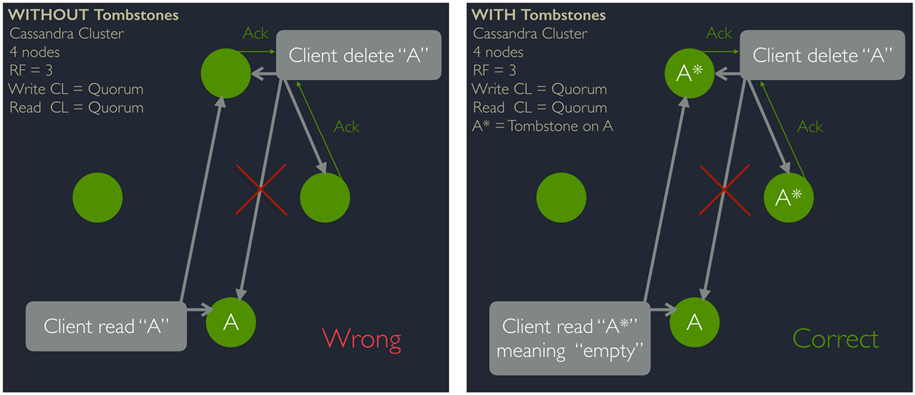
同时,如果集群内的节点发生了频繁上下线、不断宕机又重启或网络连接断断续续的情况,同时还有用户的读写请求不断进来,在集群恢复正常以后,节点间的数据一致性势必是大规模错乱的。上文中所属的读修复机制,虽然可以用来保障读取的最终一致性,但本质上是增量修复,依赖源源不断的读请求来慢慢修复其中的错误,这难免会拖累性能,降低读取速度。
为此,Cassandra提供了逆熵机制(Anti-entropy)来手动恢复节点间的数据一致性,即全量修复。这一机制需要外部触发才会执行,例如在集群恢复正常后人工触发一下,或者搞个定时脚本每隔一段时间就执行一次。
逆熵机制运行时,会比较所有节点内的所有数据,然后依据修改的时间戳从中决策出最新版本,并将当前数据的最新版本应用于所有的副本节点。这一过程通过默克尔树(Merkle trees)来实现。
当逆熵机制被触发后,会在所有的节点内依据其当前存放数据生成一棵默克尔树。默克尔树是一棵哈希二叉树,其叶子节点内存放的即为当前Cassandra节点内所有数据的hash值,每一个叶子是一条数据的hash值。然后依次往上,每一层父节点都是其子节点的hash值总和的hash值。如下所示:
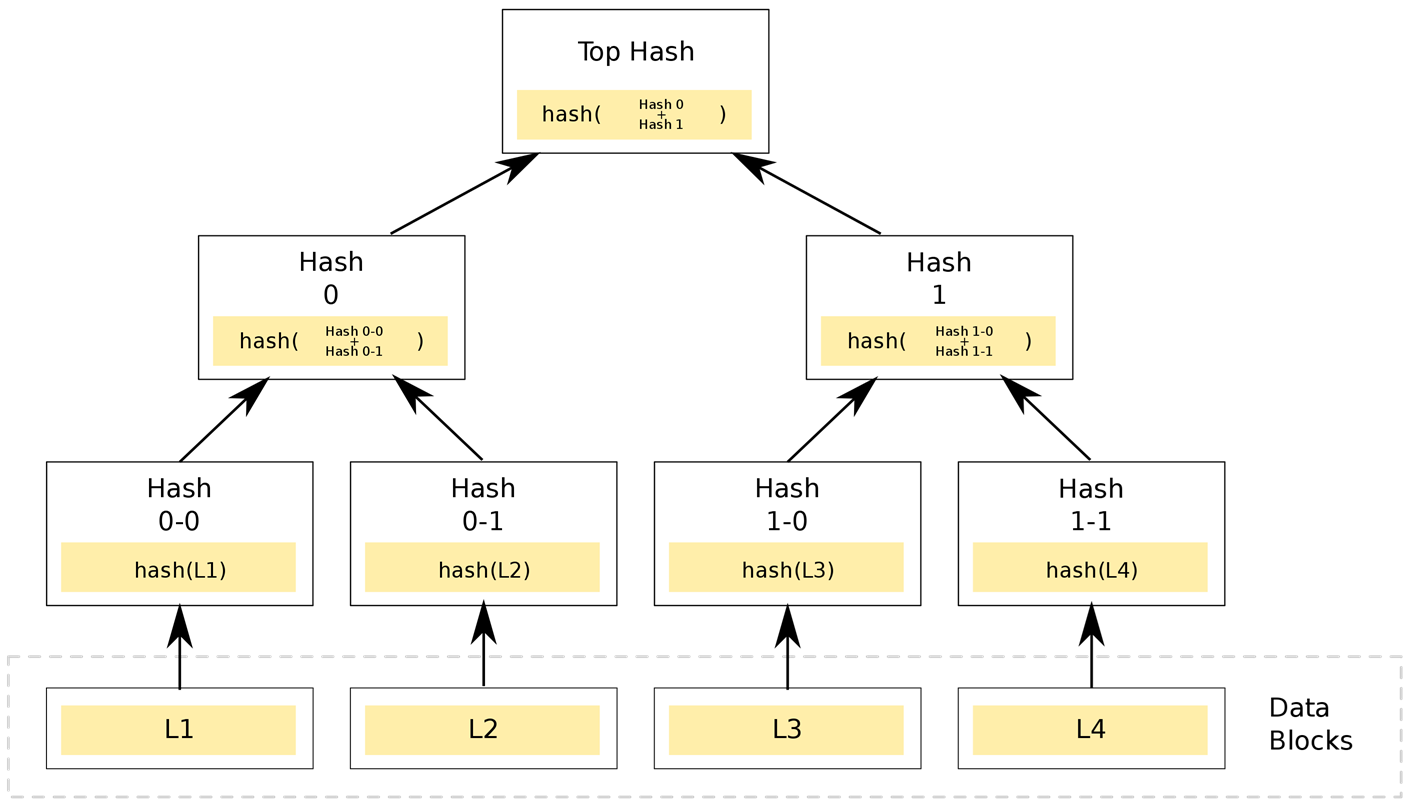
当进行比较时,如果两个节点的默克尔树的根节点的hash值相同的话,则说明两个节点内存放的数据是一致的,就不用再往下比较了。如果不同的话,则依次往下比较不同的节点,找出不同的数据,然后再进行版本决策,选出最新版本并覆盖到所有存有旧版本数据的副本节点。
为简化理解,上文省去了很多概念。实际上,Cassandra可以依据用户的一致性保障需求,设置不同的一致性等级。在不同的一致性等级下,上文所述的机制可能会被选择性执行,亦或者执行的强度有所不同。本文仅作原理性概念阐述,详细探讨可参考如下文章:
Cassandra的一致性分为读一致性和写一致性可以分别配置。同时还考虑多数据中心或多机房(datacenter)场景下,在不同机房节点间的数据一致性的保障需求。详细可参考:How is the consistency level configured?
Scylla DB是用C++重写的Cassandra,同样是一个AP数据库,性能是Cassandra的10倍,同样实现了上文所述的一致性保障机制,设计架构上可能有所不同,但整体原理是相同的。而且他们的文档写的又好又全,非常容易理解(商业软件就是比开源的好doge),本文中很多图示就借鉴自他们的文章,感兴趣的可以看下,强烈推荐:ScyllaDB Architecture
0x02 我的数据库是CP还是AP?
如下图可供参考:
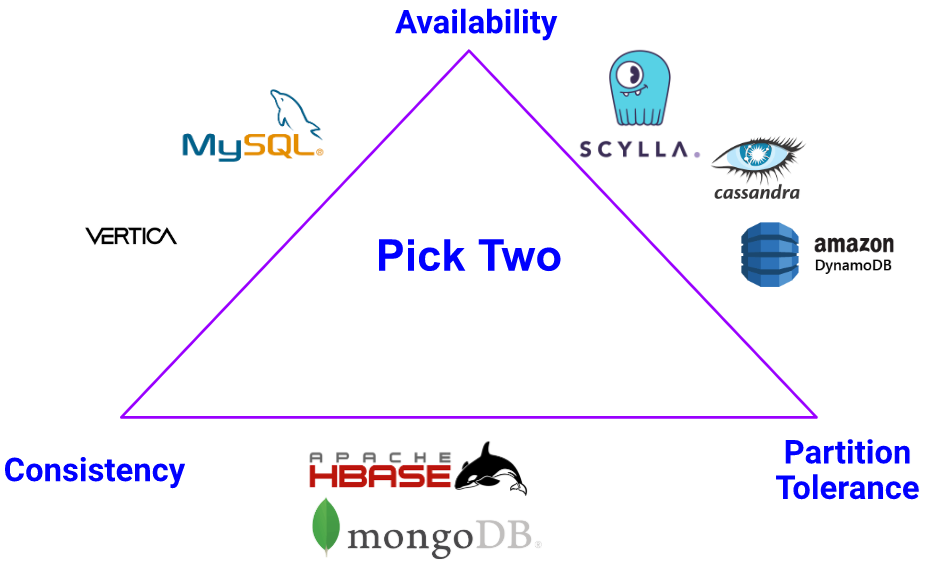
你可能会好奇,为什么MySQL归在了CA,明明我们的MySQL也有主库从库,好像也是分布式部署。原因很简单,在默认情况下,MySQL的主库和从库,只有主库在对外提供读写服务,从库就简简单单地是个备份,没有流量的。所有的读写请求都发到主库,只有在主库挂了之后,从库才会接着补上。所以说虽然有两台机器一主一从,但从外部看来其实还是单点的,从库的宕机、延迟或分区,不会影响整体可用性和一致性。MySQL本身就不是一个分布式数据库,所以默认情况下将其归为CA数据库。
如果你给MySQL上了花活,做了主从库的读写分离,那此时MySQL会转变为一个AP数据库。因为MySQL的从库是通过定时拉取主库的binlog来完成数据同步的。在主库完成数据写入,但从库的IO线程还没来得及拉取binlog完成更新的这段时间内(主从延迟),主从查询的数据是不一致的。
花活可参考:
0x01 分布式一致性共识算法
分布式一致性共识算法旨在解决分布式系统中数据的一致性问题,在分布式系统中,使得所有节点对同一份数据的认知能够达成共识。
如上文所述,根据CAP理论,绝大多数的互联网场景都是优先保障可用性,即AP模式。分布式一致性共识算法的目标就是在尽可能少牺牲C(一致性)的情况下,尽可能地提升A(可用性)。
0x00 Gossip
Gossip协议是一个去中心化的点对点传输协议,其机制非常简单,以给定的频率,集群内的节点随机选择一个其它节点,共享任何信息。跟新冠的传播方式是一样的,你感染了,然后出门游玩,就会在你接触的人群中随机选择一些幸运儿来共享你所携带的病毒。然后病毒在这些幸运儿的体内复制,再沿路选择幸运儿进行传播。
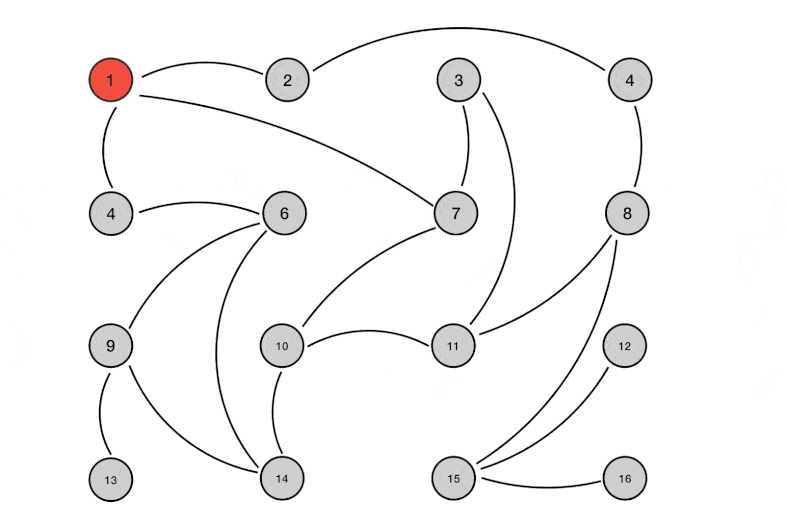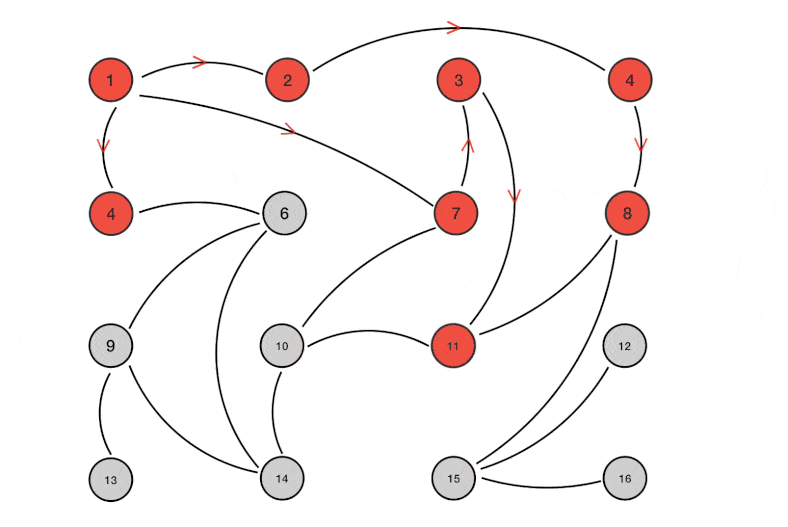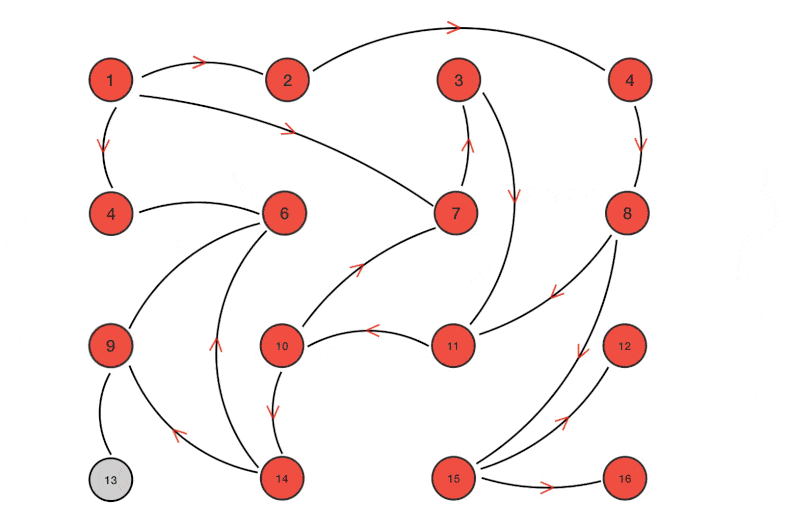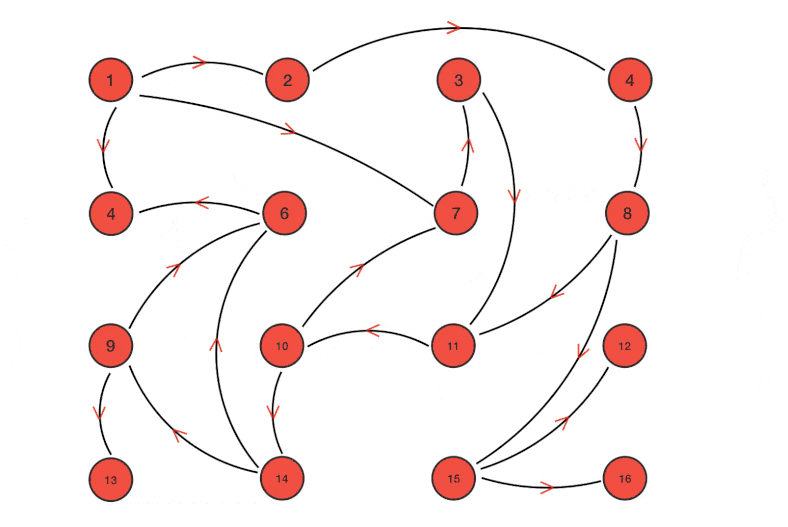
Gossip算法可以用来实现一个分布式最终一致性协议,因其去中心化的特性,非常适用于Cassandra这种无主结构的AP数据库,因此正如我们上文所述,Cassandra的提示移交机制即是通过Gossip算法来完成节点与其副本节点之间的数据同步。基本流程可以简述为集群内的节点,随机选择一些其它节点,并向其推送当前节点内的数据版本号,其它节点收到版本号后与自身内部数据的版本号进行对比,如果推送过来的版本新的话,就更新,如果旧的话,就将自己保存的较新版本的数据推送给对方。
此外,Gossip算法还可以用于集群中节点的失败检测,以Redis集群为例,集群内的主节点都会有其对应的从节点,所有的写入操作均在主节点内完成,然后再同步到其所对应的从节点中。集群内采用Gossip机制来完成节点间的探活。简言之,就是集群内的节点定期问一下集群内的其它节点,「你还活着吗(PING)」,其它节点回复活着(PONG),就没有问题。如果有节点长时间没回复,那当前节点就会认为它已经挂了。如果集群中有足够多的节点认为一个节点已经挂了之后,那集群就会把它剔除掉,并选举一个从节点来取代它的位置。
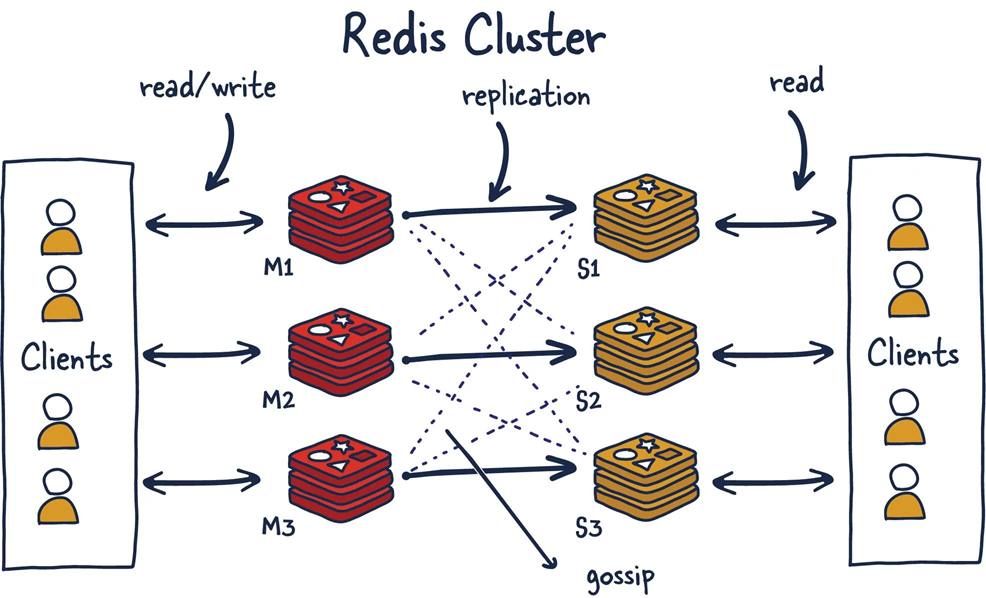
考虑这么一个情况,如果在上图中的集群发生了网络分区,分成左右两个分区,分区内的网络是通的,分区间的网络断掉了。左分区内包含M1, S2, S3三台机器,右分区内包含M2, M3, S1三台机器。此时,对左分区内的机器而言,发现M2, M3掉线了连接不上了,于是就把S2, S3两台原本是M2, M3的从库提升为主库,对外承接服务。对于右分区而言,发现M1掉线了,于是在右分区之内就把S1提升为主库。这样,集群内6台机器就全都成了主库。
假设,现存这样一组键值对foo=bar,网络分区发生前存在M1内,S1内有相同的备份。网络分区发生后,左分区内右M1,右分区内的S1被提升为主库,记为M1’。此时M1和M1’内的数据是相同的。如果一个请求,设置foo=bar1访问到左分区,则M1内的foo被改为了bar1,M1’仍然为bar。当左右分区之间的网络连接恢复之后,两个分区内的机器将会重新进行聚合,此时就会有两个M1节点,而且都是主分区,但其中的数据不一样,这个时候也不知道采用谁的数据合适,这个现象就叫脑裂(split brain)。
为了预防脑裂发生,一般会设置集群内的节点数量为奇数个,比如7个节点,当网络分区发生时,总会被分为一个节点多的分区和一个节点少的分区,比如左分区4个右分区3个。发生分区后,节点多的分区会进行从节点到主节点的提升,而节点少的分区则不会。分区消除后,则一切都可以以节点多的分区内的数据为准。对Redis而言,一个最佳实践则是设置奇数个主节点,每个主节点配备两个从节点。
0x01 Raft
我的建议,不用看我下面写的那些废话,点点下面这个演示页的continue,直观又生动地就能把这个算法看明白。写这些废话的目的,是万一哪一天出去跟面试官吹牛逼的时候,能有一个快速查阅并激起回忆的草稿。
需要注意的是,上面的演示动画,并不包括预投票机制、集群扩缩容时的leader选举以及数据一致性同步等问题的讨论,但此块内容在算法的工程实现中又很重要,其可以通过下文「预投票机制」「集群扩缩容」和「数据一致性同步」三节学习。
0x00 算法简述
在raft算法治理下,一个集群内的节点可以有三种状态(state),follower, candidate和leader。
集群内的节点最初都是follower,如果一个follower在设定的时间内,没有监听到来自的leader的心跳的话,那就会变成candidate,发起leader选举(election)。follower和candidate之间的区别,在于candidate有被选举权。
变成candidate之后,这个节点会向集群内的其它节点广播选举请求,请它们推举自己成为当前集群的leader。其它节点在收到这个选举请求之后,会进行投票,所有的投票最后都会汇聚在发起选举的这个candidate里面。如果这个candidate收到了集群内超过半数以上节点的选票,那么就会自动晋升为leader。
leader和其它节点的区别在于,leader可以处理写请求,而其它节点只能处理读请求,而且一个集群内的leader有且只有一个。如果一个follower节点收到了来自客户端的写请求,那么其会通知客户端,写请求不能发到我这,同时给出leader节点的地址,要求其向leader节点发出请求。
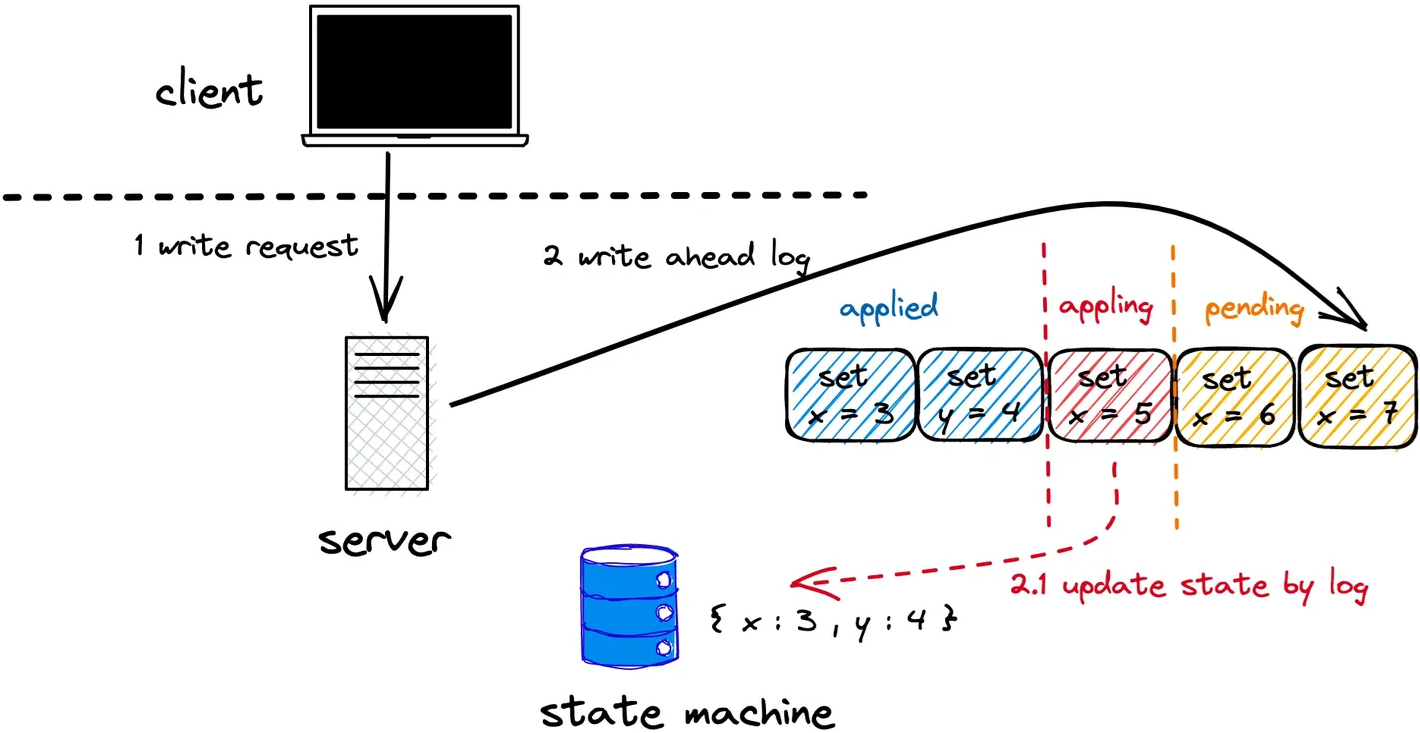
当一个写请求,被发到leader节点之后,leader节点会先将其保存在当前节点的预写日志(write ahead log)里面。写进预写日志里面的数据,并不实际生效,读请求来了读到的还是之前的数据。
此后,leader节点会向集群内的其它节点广播这一条写请求,这个过程被称之为提议(proposal)。集群内的节点在收到这一请求之后,会通过一定机制判断该节点当前的数据版本是否能够合并当前写请求。如果能的话,则将这一请求同步写到当前节点的预写日志内,并给leader发送回复,表示能够合并。
如果leader节点收到了集群内超过半数节点发来的能够合并的回复,那么leader节点就会对当前请求发起commit。commit之后,这条写请求的结果才算真正生效。同时,向客户端发送回复,表示写成功。
在leader完成提交之后,也会向其它节点发出指令,其它节点随后也会完成commit,此时数据修改正式在集群内的所有节点生效。
上述写操作流程,先后经历了proposal和commit两个阶段,proposal阶段预写日志、发起表决,commit阶段使修改正式生效,这就是所谓的两阶段提交机制。预写日志的目的则是为了保证节点内数据修改的顺序一致性。
上述写操作流程在raft算法中则被称为日志复制(Log Replication)。
0x01 leader选举
raft算法的leader选举,由任期(term)和选举超时时间(election timeout)这两个变量来进行控制。在一个任期内,一个节点只能投票一次。同时,如果超过选举超时时间还没有收到来自leader的心跳的话,那么当前follower就会变为candidate,发起leader选举。
一开始,所有节点都是follower,每个结点内都保存了一组term和选举超时时间。为了避免所有节点同时变为candidate发起选举请求,选举超时时间是在150ms-300ms之间选择的一个随机数,每个节点都不一样。同时,最初所有节点的term值都为0。
此后,选举超时时间最短的那一个,首先超时,变成candidate,并将其自身的term值加一,向集群内其它节点,发起term=1任期内的投票,并附上当前节点内的数据版本。如果一个follower节点在当前任期内还没有投过票,而且candidate节点的数据版本相同或者更新于该节点,则该节点就会把票投给这个candidate。然后重置自身的选举超时时间,并将自身的term值也+1,避免在当前任期内重复成为candidate增加竞争。
当这个candidate收到超过一半的票之后,则自动晋升为leader,然后定期向集群内的其它节点,发送心跳。心跳的发送频率则是由心跳超时(heartbeat timeout)来控制的。follower节点,每次收到心跳,都会重置其选举超时时间,保证在leader存活的情况下,不会发起新的选举。
如果leader突然挂了,那么集群内剩余节点中,选举超时时间最短的那一个,首先超时,变成candidate,发起新一轮选举。此时term值+1变成2。重复上述选举流程,推举新的leader。
考虑一个极端情况,如果有两个节点随机生成的election timeout差不多或干脆相等,那么同一时间集群内就会出现两个节点同时晋升为candidate,并发起各自的选举。而且此时集群内剩余的节点,又正好均分成了两部分,分别投给了这两个candidate,导致二者在此轮选举中的选票相同。此时,对于这两个candidate而言,本轮选举就会直接作废。在等待集群内任意节点的另一次election timeout结束后,重新发起选举,直到选出leader为止。这种情况被称为split vote。
预投票机制
我们再来考虑一个极端情况,一个有ABCDE共5个节点的raft集群,当前状态下A是leader,其余是follower,集群内所有节点的term值都等于1。突然,网络分区发生了,整个集群被分为了两个分区,分区内网络互通,而分区间网络不互通。此时,
如果AB在1分区,CDE在2分区(旧leader在节点少的一个分区)。AB完好如初,但CDE发现收不到来自leader A的心跳了,此时,分区2中就会发生一次leader选举。正好,CDE三个节点都投给了C,满足半数节点投票的需求,C被推举为分区2的leader。此时分区间的网络是断的,有新leader产生的消息A和B收不到,整个集群就会有两个leader,每个分区一个。在分区1中,term=1,A依旧是leader。在分区2中,term=2,C是新leader。
当网络分区恢复之后,分区间的网络又重新连上了。此时A和B就会收到来自C发来的心跳,C发来的心跳信息中包含当前的term值,A和B发现,自己的term值小于C的term值,此时A和B就会认同C为新leader,A的身份也会自动降为follower。
但如若ABC在1分区,DE在2分区(旧leader在节点多的一个分区)。ABC完好如初,DE收不到来自leader A的心跳。DE就会发起一次leader选举,但是在分区2内,所有的节点加起来票数也不够整个集群的一半,那每轮选举就都会作废,永远也选不出leader来。此时就有两种方案来解决这一问题:
其一,放任不管。D和E之间会不断交替成为candidate并进行leader选举,每次term值都+1,但每次选举都会作废,分区2内的term值会无限加加加。
当网络分区恢复之后,分区1内的term值依然等于1,假设分区2内发生了9次leader选举,term已经到10了。此时分区2内的节点,重新收到来自leader A的心跳,发现leader A的term=1,而自己的term=10,那么依旧不妨碍DE节点成为candidate重新发起选举。此时,D发起了term=11的选举,ABC三个节点自身term=1,也会重置为11,并开始为D投票,选出新的leader D。新leader D选出来后,老leader A也会自动降级为follower。
在这种模式下,每次网络分区恢复之后,都要重新选举一轮leader。
此番过程可以通过如下可视化来进行演示,右键包括当前leader在内的其中3个节点,点击stop,观察剩余2个节点行为。然后再恢复其中一个节点,观察当前集群行为。
其二,引入预投票机制(pre-vote protocol)。在节点D准备成为candidate前,会先在集群内发起一轮预投票,结果显示在当前分区内,怎么也凑不齐半数以上的节点,那节点D就会放弃成为candidate,term值也不会改变。
当网络分区恢复之后,所有节点的term值依然都是1,大家依旧认同A是leader,仿佛什么事情都没有发生。预投票可以有效解决异常网络环境下leader频繁切换的问题。
集群扩缩容
上述的leader选举,有一个很大的认知前提就是,在选举过程中,大家都知道当前集群内一共有多少节点,由此在投票的过程中才能知道多少才是大多数。亦因如此,raft集群中的每一个节点内都会保存一份当前集群内所有节点地址的列表。
但如果我们要对集群进行扩缩容呢?假设一个集群一共有123三个节点,其中3是leader,我们需要对集群新加编号为45的2个节点。那么我们必须将新的集群节点名单推送到当前集群内的所有节点,让大家都知道集群内的节点数量变了。
在添加新节点之前,123节点内保存的节点列表记为,新推送的节点列表记为。扩容的最初,123三个节点内保存的节点列表为,45两个新节点内的列表则被初始化为。
扩容的第一步,我们把45两个节点加入集群,并向123三个节点推送新的节点列表,此时所有节点的term都等于1。
我们同时向123节点推送新的节点列表,但123节点因为网络延迟不一定能同时收到。假设收到的顺序是321,那么此时,就一定会有一个时间段,3收到了12没有收到。在这个时间段内3, 4, 5所认可的集群内的节点数量是5,1, 2所认可的集群内节点数量依旧是3。
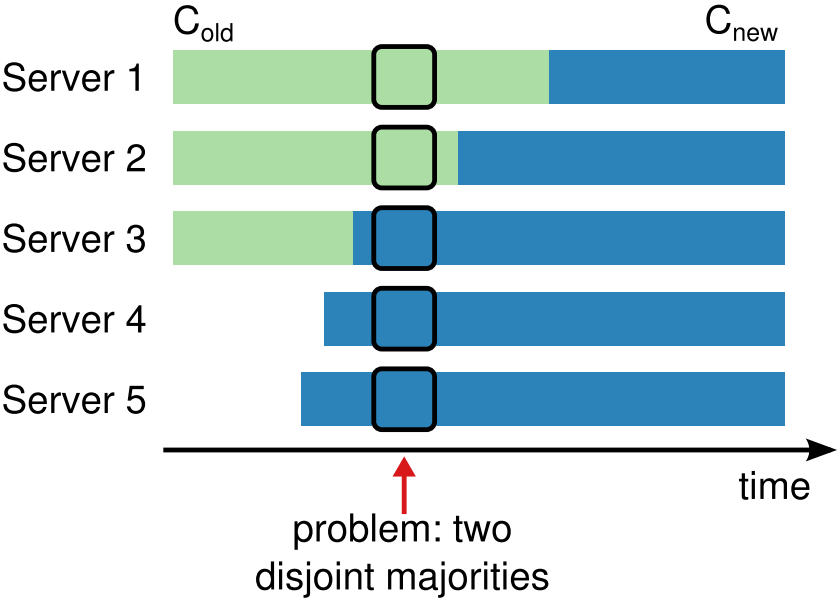
考虑一个极端情况,就在这个时间段内,leader 3掉线了,触发了leader选举,同时,节点1和5又恰巧同时成为candidate,同时发起了下一任期(term=2)内的选举。当他们成为candidate后,leader 3网络好了,又回来了。此时,对于candidate 1而言,他认为当前集群内有3个节点,所以只需要收集到包括自己在内的2张选票就可以成为leader。而对于candidate 5而言,他认为当前集群内有5个节点,他需要收集包括自己在内的3张选票才能成为leader。而又恰好,candidate 1收到了来自follower 2的选票,凑齐了3的一半,成为了term2的leader。而candidate 5收到了来着follower 3, 4的选票,凑齐了5的一半,也成为了term2的leader。这时,集群内就出现了两个leader,发生了脑裂。
为了避免这种情况的发生,有两种解决方案。
其一,就是单节点成员变更,每次只向集群中增加或删除一个节点。比如说以前集群中存在三个节点,现在需要将集群拓展为五个节点,那么就需要一个一个节点的添加,而不是一次添加两个节点。
一个一个添加节点的好处就是,如果真的发生了上述问题,那么在进行leader选举时,内的大多数节点与内的大多数节点一定存在重合,也就是说最后一个人的选票一定可以定胜负,选出唯一的leader。
如下图所示,在所有节点达成集群整体数量共识前的那个微小的时间段内,有共识的即为蓝色框中节点,有共识的即为红色框中节点,枚举出了集群从3个节点加到5个节点以及从5个节点减到3个节点的情况:
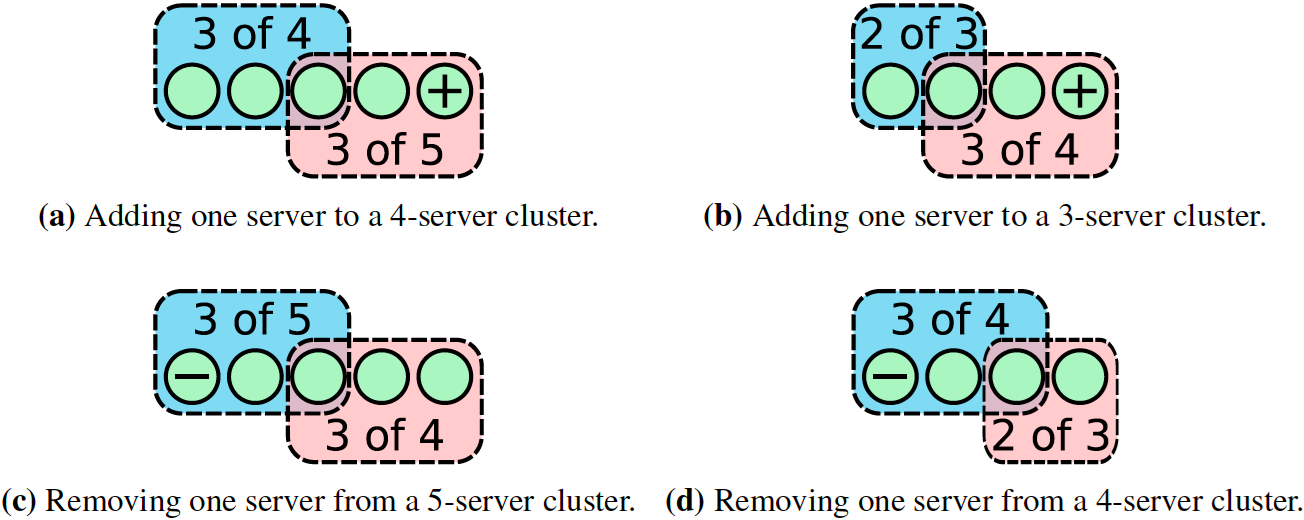
目前绝大多数Raft实现都是采用单节点成员变更的方式完成集群扩缩容。
其二,就是多节点联合共识(joint consensus),这也是raft论文中作者提出的一种算法。使用多节点联合共识即可一次向集群中增减多个节点。
假设一个初始3个节点的集群,当前的节点列表为,我们需要下掉节点1,并扩容2个新节点4, 5,即新的节点列表为。我们将这两个列表之和记作。
节点变更时的算法流程如下
- 向leader节点推送集群变更请求及新节点名单
- leader节点基于当前节点列表和生成,并向集群内所有follower节点广播
- follower节点收到后,立即生效,并作为此后leader选举时判断大多数的依据,并向leader节点发出ACK表示成功收到
- leader节点等收到列表中的大多数节点的ACK消息后,向新节点名单中的节点推送新名单
- 此后即可安全地从集群中移除减少的节点
依据列表判断大多数的过程是同时基于其中的两份列表的。也就是说,需要同时满足和的大多数才算的大多数。对于列表而言,几个判断示例如下:
| 投票 | 是否大多数 | 是否大多数 | 是否大多数 |
|---|---|---|---|
| 1- 2- 3+ 4+ 5+ | 否 | 是 | 否 |
| 1+ 2+ 3+ 4- 5- | 是 | 否 | 否 |
| 1+ 2+ 3- 4+ 5+ | 是 | 是 | 是 |
假设说,leader节点在向集群广播的过程中掉线,一部分机器收到并生效了列表,而另一部分机器没有。此时因为leader的掉线,集群需要重新进行leader选举。
对于收到配置的机器而言,选举为leader,需要的大多数才能生效,而对于没有收到的机器而言,则需要的大多数才能生效。此时,对于双方而言,想要生效都必须满足收到了来自中节点大多数的投票,由此即保证了在这一阶段不会同时选出两个leader。
leader节点推送的前提是收到了来自列表中大多数节点的ACK,也就是说列表已经同时应用于和的大多数机器。
同理,在推送的过程中,如若发生leader选举,对于没有收到依旧保持的节点而言,其数据版本小于当前集群的大多数节点(收到的节点)的数据版本,由此是不会投票给它的,也就是说这部分节点永远成不了leader。对于收到的节点而言,则不管有没有收到,都同时需要中大多数的投票才能选举为leader,同样保证了在这一阶段不会同时选出两个leader。
0x02 日志复制
日志复制的根本是要保证,一条写请求要周知到集群内超过一半的节点,才能代表写成功。
如上所述,在正常情况下,一个集群只有一个leader,所有的写请求都交由leader节点来进行处理。leader节点会先将写请求保存到自己的预写日志里,然后在下一次发送心跳的过程中,将其广播出去。如果收到超过集群一半的节点的确认回复,那么才会真正触发提交使写操作生效,并随着下一次心跳使得变更在所有follower节点提交生效。
假设一个集群有ABCDE 5个节点,A是leader,一条数据x=0已经在所有节点生效。此时发生了网络分区,AB在一个分区,CDE在另外一个分区。如前所述,此时就会在CDE节点内发生一次leader选举,并推举C为leader。这样一个集群就出现了AC两个leader。
在这种情况下,如果有一个client向A节点发出写请求SET x=1,此时这条请求被写进A的预写日志里,然后向集群内剩余节点广播,但只收到了来自B的确认回复,不满足超过集群内半数以上节点的条件,由此这条写请求失败,但会一直保存在A和B的预写日志里。此时,从ABCDE这五个节点读取x的值都会返回0。
此后,又有一个client向C节点发出写请求SET x=2,这条请求被写进C的预写日志内,同时向集群内剩余节点广播,收到了来自DE两个节点的确认回复。此时CDE三个节点满足了超过集群内半数以上节点的条件,这条写请求被提交,并随着下一次心跳在DE两节点内生效。如若客户端从CDE节点读取x的值,都会返回2。如若客户端从AB节点读取x的值,则会返回0。
此时,就出现了数据不一致的情况。
当网络分区恢复之后,AB发现CDE节点的term数更高,而且已经有了更新任期的leader C,那么节点A就会从leader降为follower,然后AB重新认定新的leader为C,并且回滚预写日志内所有未提交的变更,SET x=1这条命令就作废了。然后AB重新从新leader同步日志,然后按照日志顺序从网络分区发生时的断点处进行回放,执行SET x=2的请求,设置新值,完成集群内所有节点的数据一致性同步。
0x03 数据一致性同步
raft算法中,实际保存数据的结构叫状态机(state machine),状态机内存储的都是最终已经提交生效的数据。集群内的每一个节点都有一个自己的状态机。状态机内的数据都是沿着预写日志内的数据从前往后依次按顺序执行下来的。
leader节点与follower节点同步数据的请求叫做AppendEntry,同时也表示leader向follower发送的心跳。每个节点内都会保存一个term值,表示自己当前认可的leader的任期,每一次的AppendEntry心跳中也会包含一个term值,表示当前发来请求的leader的任期。
每个节点内会存储一个commitIndex表示当前节点已知的最新的数据版本,这个值在节点初始化的时候被设为0,此后每写一条数据都会将这个值+1。每一次的AppendEntry中也会包含一个prevLogIndex表明当前写请求的前一条请求的日志版本。
当一个follower节点收到来自leader节点的AppendEntry心跳后,如若,
AppendEntry内的term值大于当前follower节点内的term值,则follower会重新认爹,与当前leader看齐,并进入下述环节3AppendEntry内的term值小于当前follower节点内的term值,则follower会拒绝leader的请求,并通知这个leader已经改朝换代了,此后这一leader节点会主动退位降为follower,向新leader看齐AppendEntry内的term值等于当前follower节点内的term值,则follower节点会通过比较prevLogIndex和commitIndex的大小,以完成数据同步,此时如若prevLogIndex == commitIndex,表明当前节点内存储的数据是最新的,可以将这条同步请求内的数据写到自己的预写日志里prevLogIndex > commitIndex,表示follower节点内的数据要滞后于leader节点内的数据,follower节点会拒绝leader节点的同步请求,当leader发现follower响应的任期与自身相同却又拒绝同步,则会递归向follower同步预写日志数组中的前一条日志,直到补齐follower缺失的全部日志后,流程回归到正常的轨道prevLogIndex < commitIndex,表示follower内的数据更新于leader内的数据,则follower会移除这部分超前的数据,已经提交的也会回滚回来,向当前的leader看齐
通过如上方式,raft可以保证各节点间预写日志数组的已提交部分无论在内容还是顺序上都是完全一致的,即最终顺序一致性。
如前所述,如果发生了网络分区,那么分区间的数据可能是不一致的,client端从不同分区节点内读到的数据也可能是不一致的。如若想缓解这一问题,只能采用类似Cassandra的读修复机制。当client向一个节点发送读请求后,该节点的回复中还会包含一个lastApplied字段,表示当前节点的状态机中已经生效数据的最新日志版本。client此时可以多从几个节点中读取数据,然后取lastApplied最大的那一条数据作为返回。
0x02 Paxos
0x00 难以理解的
Paxos算法以它的难以理解而闻名,Raft算法的作者就是觉得Paxos实在是太难理解了,所以给他的论文起名叫In Search of an Understandable Consensus Algorithm(寻找一种容易理解的一致性算法)。
Paxos的原始论文The part-time parliament,有33页之多,它的末尾写着一句话,让我印象深刻,Received January 1990; Accepted March 1998,也就是说这篇论文是在1990年1月份提交的,直到1998年3月份才得以出版,也就是说审稿人花了整整8年时间才读懂并最终接纳了他的论文。
The part-time parliament一文中含有大量的数学证明,看上去都不像是一篇计算机学科的论文。于是,为了让计算机专业的学生能够读懂他的论文,2001年,Paxos算法的原作者发表了论文Paxos Made Simple,简化版的原始论文,仅有14页,去除了其中大量的数学证明,旨在使大多数人可以读懂。这篇论文的摘要部分就一句话,The Paxos algorithm, when presented in plain English, is very simple.(用人话讲述的Paxos算法,非常简单 doge)。
本文Basic Paxos一节的主要参考资料是Google TechTalks发布的视频The Paxos Algorithm,只有25分钟,通俗易懂。Multi-Paxos一节的参考资料是Raft算法作者Diego发布的视频Paxos lecture (Raft user study),66分钟左右。这个视频的专业度要强一些,理解起来自然也会困难一些,但是讲得特别全,有很多独家内容是网上其它参考资料所包含不到的。建议先看Google的视频初学,先明白是怎么一回事,然后再看Diego的视频加深理解。
0x01 应用场景
Paxos算法主要用于在一个分布式系统中就某一数值快速安全地达成一致。考虑一个分布式存储服务,为了保证可用性,我们对同样的数据设置多个副本,并保存在多台机器上。一条写请求,会发送到其中的某台机器,然后收到写请求的这台机器再将这条数据同步到集群内的所有节点中。
在此场景下,对于一个节点而言,其内部应有一个一致性同步模块,用于与集群内的其它节点完成数据一致性同步,一个状态机,用于持久化数据,以及一个预写日志队列,预写日志的目的则在于保证应用到状态机内的数据是顺序一致的。一个典型的写入流程如下所示:
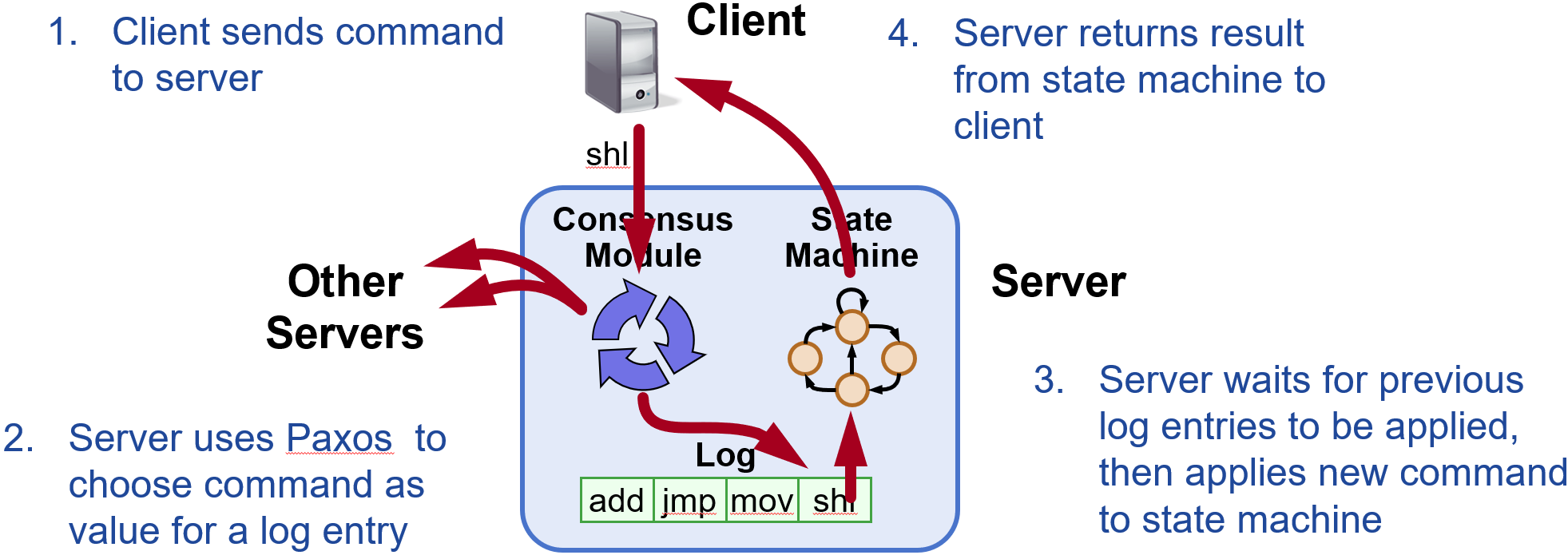
在分布式系统中,写请求可能被发送到集群中的不同节点,节点之间进行同步的过程中,亦有可能受到网络环境的干扰,一条同步请求,可能会丢失,也可能会被重复发到某一台机器上,各副本节点收到的顺序也有可能与发送的顺序不相符合。基于Paxos协议的数据一致性模块就主要用于在这种复杂多变的网络环境下,就一条数据的最终结果在整个集群内部达成一致。
在这个模型中,每一条写进预写日志的entry都是经过Paxos一致性模块,在整个集群中达成共识的。因为Paxos协议只针对一条数据达成共识,所以上图中每一个log entry都对应一个用于决定共识的Paxos instance。当共识达成时,这条日志才被写进预写日志序列,继而被应用到状态机完成持久化。
0x02 Basic-Paxos
Paxos算法的基本思想与Raft相同,都是基于大多数原则,每一次写请求都需要经过集群内大多数节点的同意,才能被最终写进状态机。Paxos将集群中的节点分为三类:
- Proposer:用来处理所有的写请求,并发起投票
- Acceptor:有投票权的节点,会接受Proposer的投票请求并进行投票
- Learner:没有投票权的节点,对所有投票的结果只能被动接受
Acceptor和Learner节点都是需要维护状态机的,也就是说要持久化保存数据的,同时可以处理读请求。而Proposer节点,可以理解为就是一个富客户端。
需要注意的是,Paxos集群中的一个节点可以同时担当多个角色,而且集群中可以同时有多个可以处理写请求的Proposer,并且不是集群中的所有节点都有投票权。一次投票,仅需集群中半数以上的Acceptor节点同意即可,Learner节点则完全没有任何权利。
一个正常的写请求,会首先发到Proposer节点,Proposer节点内会维护一个PROMISE id,这个id是全局唯一且递增的,每有一个写请求就会发生递增。同时,Paxos允许集群内有多个Proposer节点,为了避免多个节点生成相同的PROMISE id,一般有两种方案,一是通过奇偶或尾数错开,比如两个Proposer节点,一个的自增序列是135另一个是246这样。二是通过纳秒级的时间戳,多节点生成同一个纳秒时间戳的概率非常低。
假设一个Proposer节点开局生成的PROMISE id是5,在收到写请求后,其会首先向集群内所有的Acceptor节点发起PREPARE。在这个PREPARE请求中,仅包含这个PROMISE id。
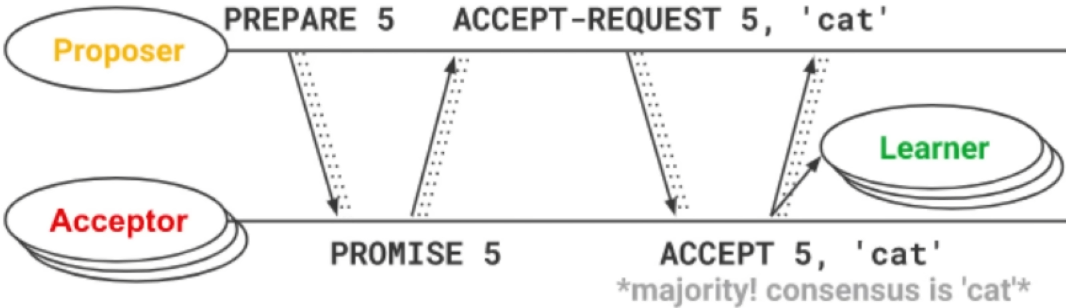
Acceptor节点在收到PREPARE请求之后,会比较发过来的PROMISE id和自身当前存储的PROMISE id,如果新的PROMISE id数值大于等于其存储的PROMISE id的话,那就直接覆盖其自身存储,并向Proposer发回确认。如果新的PROMISE id数值小于其当前存储的PROMISE id的话,则直接忽略掉当前请求。
Proposer节点在收到大多数Acceptor节点发回的确认后,会向其推送写数据请求(ACCEPT请求),这个请求中会包含达成一致的PROMISE id和新的数据cat。Acceptor节点在收到这一请求后,会将数据cat写进自己的状态机。并向集群中的Learner节点推送这一数据,Learner节点被动接受。同时,向Proposer节点发回确认,Proposer通知客户端修改成功。
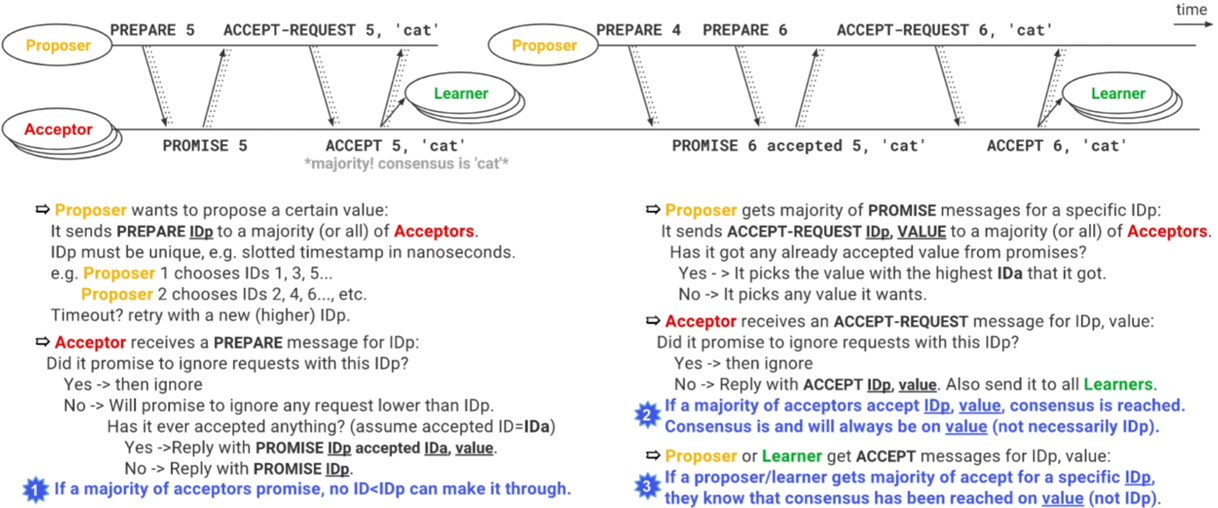
如前所述,一个集群中可能存在多个Proposer,Proposer之间可能通过奇偶来区分其发出的PROMISE id序列。在上述数据写成功之后,集群内大多数Acceptor已经认可当前最新的PROMISE id=5。此时,如果另外一个Proposer向其发出写请求,同时其PROMISE id是按偶数递增的,当前值是4。预投票请求被发出后,自然会受到集群内大多数节点的忽略。当Proposer超过一定时间没有收到大多数Acceptor的确认之后,就会将其PROMISE id递增,并发起下一次预投票,按偶数递增的下一个id是6。

Acceptor在收到PROMISE id=6的PREPARE请求后,发现此前已经就值为cat达成了共识,于是在向Proposer节点发回确认的过程中,会带上cat这一此前已经达成共识的数值。Proposer节点收到这一确认后,即认为自己所携带的数据版本落后于集群内已经达成共识的数据版本,随即选出PROMISE id最高的一个Acceptor发回的值,作为最终共识,并通过下一次ACCEPT请求发送给集群中的Acceptor节点。
整体的算法流程如下图所示:
竞争(Contention)
因为Acceptor在收到一个更高的PROMISE id后,会选择忽略这个PROMISE id之前的请求。同时一个集群中又有多个Proposer,由此就有可能产生竞争。并且在极端情况下,这个竞争可能变成死循环,一直解不开。
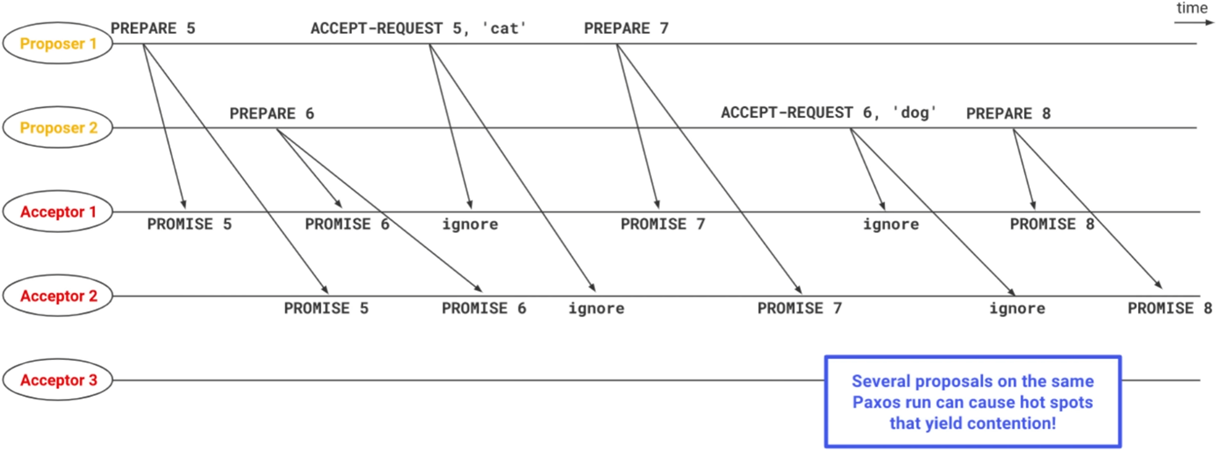
为了避免上述情况的出现,当一个Proposer连续发出多次请求都被忽略后,会进行避让(backoff),每次避让的时间是以指数的方式增长的。在上述情况中,首发的Proposer 1节点会首先达到请求忽略次数的避让阈值,触发避让,此时就会留给Proposer 2足够的时间完成一次完整的共识过程。
在很多资料中,这种竞争又被成为活锁(Live lock)。
0x03 Multi-Paxos
如上所述,Basic Paxos有几个缺点:
- 每一个节点在收到写请求后,都会化身为一个Proposer发出提议,如果集群中出现了太多的Proposer,那发生竞争的可能性就会显著增大
- 每一条数据的选举,都需要PREPARE和ACCEPT两次RPC请求
为此,就有了Multi-Paxos算法,主要为了解决上述两个问题:
- 选主,选出一个leader节点,集群中只有这个leader节点可以处理写请求(作为Proposer),集群中同时只能有一个Proposer,消除了Proposer之间竞争的问题
- 消除绝大多数的PREPARE请求
- 只在节点刚当选leader的最开始PREPARE一次
- 其它写日志的同步,仅使用ACCEPT请求
leader选举
leader选举的过程,论文中给出了一个简单的实现:
- 给集群中的每个节点都赋予一个id,这个id是一个整数
- 每个节点每隔T毫秒就会向集群中的其它节点发出心跳请求,这一请求中会携带自己的id值
- 节点收到来自其它节点的心跳后,会比较自身id值与其它节点id值的大小,然后认id最大的为自己的leader
- 如果一个节点超过2T毫秒后,依然没有收到一个携带id比它大的心跳请求,那它自己将成为leader
在集群网络良好的状态下,这可以选出唯一的leader。
但假设说网络不好,一个有12345五个节点的集群,5按理来说应该是最终的leader,但5发给4的两次心跳请求恰好都丢失了,那么4也会认为自己是个leader。此时集群中就会出现4和5两个leader。
当然一个集群中出现两个leader对Multi-Paxos来说也没有问题,就是相当于basic Paxos中有两个Proposer的场景,一样可以工作,只不过如上所述可能会出现竞争。
对于leader节点而言,其可以作为Proposer节点处理写请求。而对于非leader节点而言,其是一个Acceptor,并将所有的写请求重定向至leader节点。
PREPARE 请求消除
Basic Paxos中,每一次的值选取都会经过一次PREPARE请求和一次ACCEPT请求。而我们现在有了leader,集群中只有一个Proposer节点,就可以只用一次PREPARE请求来确认当前集群中预写日志队列中下一条日志的起始位置,当这个起始位置达成共识后,未来就可以只发送ACCEPT请求来向集群中其它节点的日志队列追加日志。
Multi-Paxos的PROMISE id从一个自增序列变成了预写日志队列id的最大值,表示当前leader节点中预写日志队列中最新一条日志的下标。leader节点会通过心跳请求广播自己的id到集群中,如果其它Acceptor节点本身携带的id小于等于leader节点的id的话,那么就会返回noMoreAccepted请求,表示你的数据是最新的。当leader节点收到来自集群中大多数节点的noMoreAccepted请求之后,在未来的调用中就不会再发送PREPARE请求。因为此时集群中的大多数节点已经就当前数据的最新版本达成了一致。
因为只有leader节点能处理写请求,所以按理来说leader节点的数据应该永远都是最新的。但如果发生了例外情况,在这一过程中,有一节点的数据版本比当前leader还要新,就会向其发回Accept Reject请求。当出现这种情况的时候,就说明需要重新进行leader选举了,当前的leader会退位,有最新数据版本的节点会成为新的leader。
日志复制
日志复制旨在实现Multi-Paxos集群中leader节点和其它Acceptor节点之间的数据同步。这一过程又被成为Full Disclosure。
首先,leader节点收到新的写入请求并在向集群内其它节点广播ACCEPT请求时,如有失败,会不断进行重试,直到收到集群内所有节点的回复为止。
其次,对于一条预写日志而言,会同时记录写入当前这条日志的PROMISE id,如果这条日志已经在集群内达成共识,那么就会将记录的这条日志的PROMISE id置为无穷大,以避免未来有Accept请求携带更大一个的PROMISE id修改掉这条数据。同时,节点内还会维护一个firstUnchosenIndex表示当前预写日志队列中,第一条没有在集群内达成共识的日志的id值,也预示着所有id比它小的日志都是完整的且都已经在集群内达成共识。
leader节点在处理写请求时,会向集群中其它节点广播的ACCEPT请求,其中会包含其自身的firstUnchosenIndex值,当前要写入的数据v,这条数据要写入的预写日志队列位置的index值,以及当前的PROMISE id。我们将这个ACCEPT请求中的值记为leader.*
对于Acceptor节点的日志队列而言,假设一条日志的index值为i,那么如果
- i ≤
leader.firstUnchosenIndex,说明当前这条日志已经在整个集群内达成共识 leader.firstUnchosenIndex< i <leader.index,表示当前日志尚未在集群内达成共识,但已经在达成共识的路上,只不过在路上的时候又有新的写请求过来了,而这条ACCEPT请求是为新的写请求准备的。此时Acceptor节点会依据leader.index的值,将这条请求所携带的日志放在正确的位置- i >
leader.index,一般不会发生,但如果发生说明当前节点日志超前于leader,说明应该重新选主了
一次ACCEPT请求之后,Acceptor节点内日志的变化如下所示:
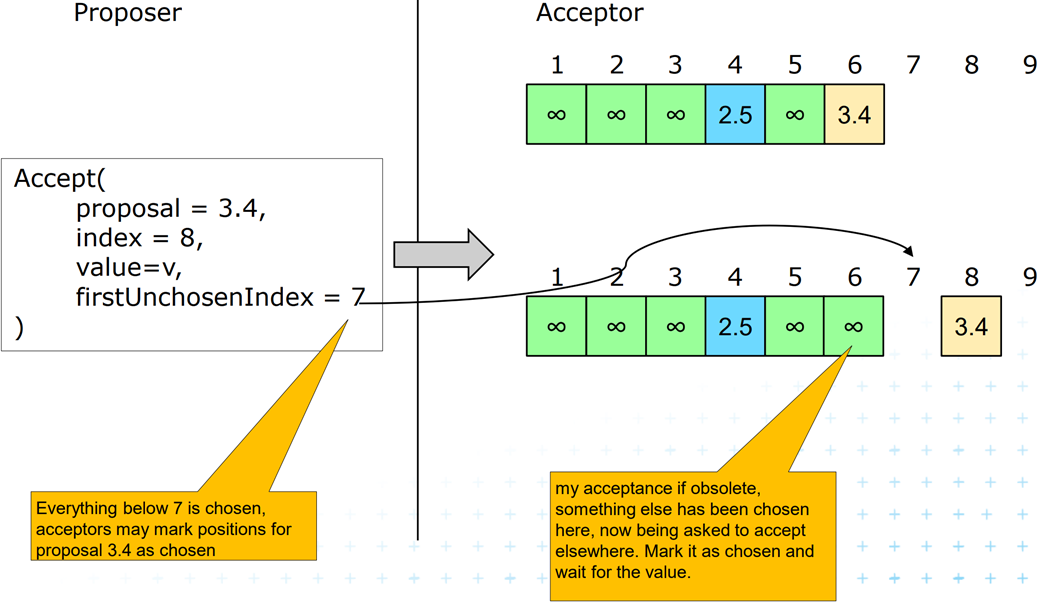
因为网络的异常,某一次的ACCEPT请求可能会彻底丢失,因此Acceptor节点可能会收到超前数据的ACCEPT请求,具体表现为Acceptor节点内保存的firstUnchosenIndex值小于leader节点当前发来ACCEPT请求中的firstUnchosenIndex值。Acceptor节点在受理这一ACCEPT请求之后,会将其所包含的数据放在正确的位置,但同时也意识到自己已经缺失了部分数据。
对于此种情况,Acceptor节点在回复leader节点的ACCEPT请求时,会将其自身的firstUnchosenIndex值一并发送给leader节点。此后,leader节点在收到这一回复之后,会比较自身与Acceptor节点之间的firstUnchosenIndex值,如果leader.firstUnchosenIndex > acceptor.firstUnchosenIndex,那么leader会对其发出回复SUCCESS(index, value),其中含有这条缺失的数据及其日志坐标。Acceptor节点收到后会进行数据补齐。如果补齐之后还有缺失的数据,那就会继续在回复中发送自己的firstUnchosenIndex,直到全部缺失数据补齐为止(leader.firstUnchosenIndex == acceptor.firstUnchosenIndex)。
Exactly-Once
如上所述,leader节点在处理写请求的时候,会先将这条请求写入自己的预写日志,然后向集群内其它节点广播ACCEPT请求以完成数据同步。同时,在收到集群内超半数以上节点对这条ACCEPT请求的成功回复之后,将其数据写入自己的状态机,表示已经成功提交,并向客户端发回写成功回复。
考虑一个极端情况,如果leader节点收到了集群内超半数以上节点对ACCEPT请求的回复,并将其写入了自己的状态机,但就在向client发出回复之前的这一刹那,leader节点挂掉了,回复没发出去。
leader挂掉之后,在经过2次心跳间隔周期后,集群内日志id最大的会成为新leader。
此时,对客户端来说就是写请求超时,他也不知道这条数据有没有写成功。于是客户端会发出重试。但是,这条数据其实已经被写成功了,就是回复丢了而已。此时,客户端就会重放上一条写请求到新的leader节点。就出现了重放。而我们需要保证的是Exactly-Once,一条写请求只能被处理一次。
为此,Multi-Paxos的客户端会对每一条写请求都赋予一个UUID,重试的时候会使用相同的UUID。而集群内所有节点的状态机和预写日志都会记录已经执行过的请求的UUID,如果出现UUID重复的话,就认为此条命令已经被执行过了,继而不会执行第二次,以保证写请求的Exactly-Once。
0x04 集群扩缩容
跟Raft一样,Paxos在集群配置发生变更时,同样可能出现脑裂问题。考虑这样一个Paxos集群,最开始的时候有P1一个Proposer节点和A1, A2两个Acceptor节点。后来我们需要对其进行扩容加上A3和P2两个新节点。
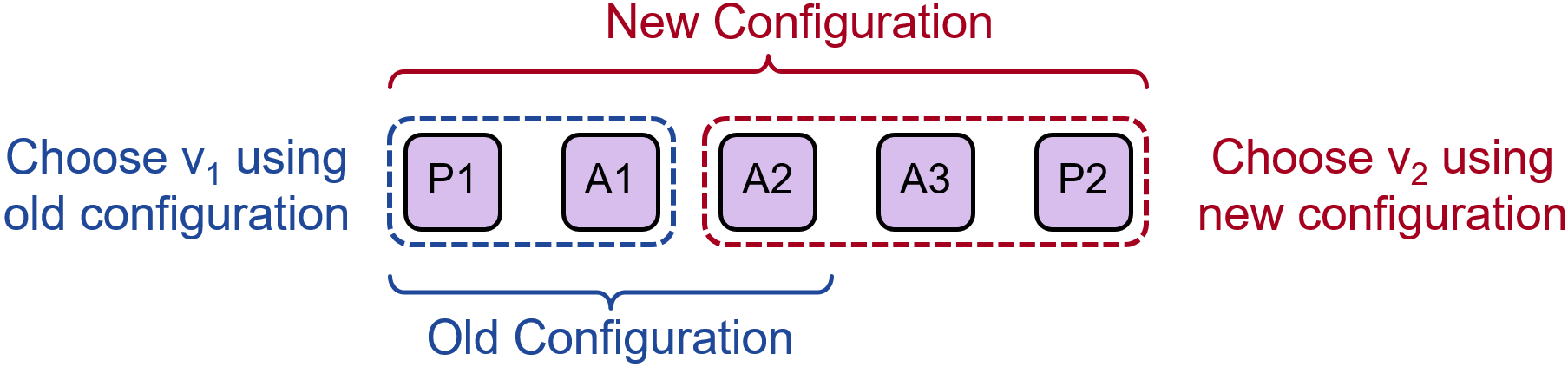
由此我们需要将新配置推送到集群中的每一个节点。假设在某个时刻,A2, A3, P2收到了新配置,而P1, A1还没有收到。但此时,有两个写请求,分别被发送到了P1和P2两个Proposer节点。
P1基于自己的配置(集群内共3个节点),在收到A1的回复后,就认为集群中的大多数已经达成共识,选出了值v1。P2基于新配置,在收到A2, A3的回复后,认为集群中的大多数已经达成共识,选出了值v2。此时整个集群就发生了脑裂。
为了解决这一问题,Paxos将集群的节点配置也都放在节点的预写日志里,而且和其它的写数据请求共用一个预写日志队列。假设最开始集群内储存的节点配置是,此后经历了两次节点变更,配置依次变为和。
Paxos的节点中会储存一个变量α,如果说集群的节点配置变更请求被写进了预写队列的索引i位置,那么直到index增长到i+α之前,所有的写数据请求都不会用新配置完成共识。如下图所示即为α=3的场景:
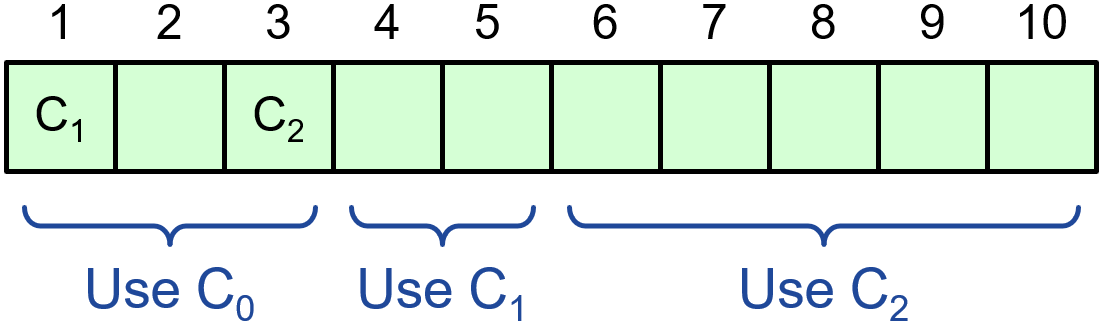
在日志索引i=1时,对新集群的配置达成了共识,但直到i=4时,才会用新配置进行投票。同理,对于索引i=3时收到的更新配置,要等到i=6时才会真正生效。
α值的选取,依赖于你觉得集群内需要多长时间才能完整地同步新配置。如果你觉得集群内节点间的延迟比较大,那就扩大α的值,使其晚一点生效。反之,就减小α的值。
这是安全的吗?这可以避免脑裂吗?
是的,可以。新配置已经在老集群内达成了共识,只不过要等一会才能使其真正生效。而新配置又天然存在于新扩充的节点内。在上例中,对于i=4的日志选取,老集群内未完成新配置同步的残余节点已经无法组成老集群的大多数,只能由新集群的大多数产生,所以就不会发生脑裂。
为什么要用α让配置等一会生效,设置α=1,使其在下一条日志选取时直接生效不好吗?
α在很大程度上决定着,在发生配置变更时,集群所能同时处理的写请求的并发度。如果α=1的话,那么当发生配置变更时,集群内所有Proposer节点都要等着新配置在集群内达成共识才能处理新的写入请求。也就是说在发生配置变更时,整个集群会暂停写入服务。
0x02 参考文献
You Can’t Sacrifice Partition Tolerance
About Deletes and Tombstones in Cassandra
Manual repair: Anti-entropy repair
How is the consistency level configured?
分布式一致性协议 Gossip 和 Redis 集群原理解析
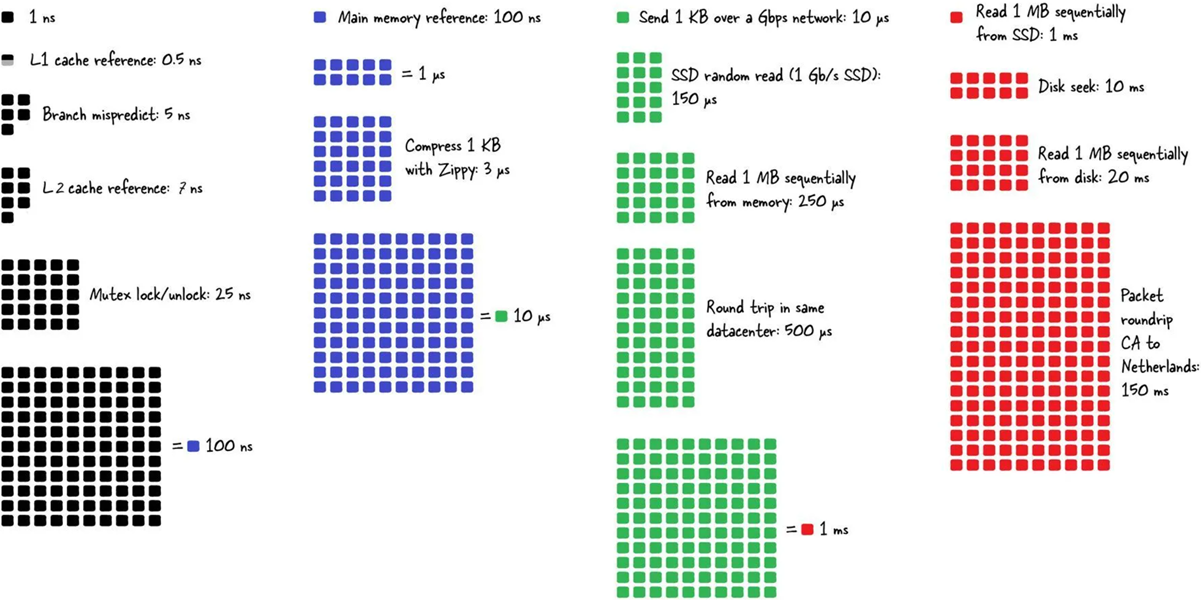
看这篇文章的时候,看到一个非常好的图,可以让你对现代计算机及网络的性能有一个直观的了解,虽然与本文内容无关,但还是想把他保存下来,以作备忘。
Raft Understandable Distributed Consensus
How does Raft handle a prolonged network partition?
In Search of an Understandable Consensus Algorithm
 支付宝
支付宝- 微信


