0x00 梯度下降法(Gradient Descent)
0x00 标准梯度下降法(GD)
假设要学习训练的模型参数为W W W J ( W ) J(W) J ( W ) Δ J ( W ) \Delta J(W) Δ J ( W ) η t \eta_t η t W t W_t W t t t t W t + 1 W_{t+1} W t + 1
W t + 1 = W t − η t Δ J ( W t ) W_{t+1}=W_t-\eta_t\Delta J(W_t)
W t + 1 = W t − η t Δ J ( W t )
其基本的策略为在有限的视距内寻找最快的路径下山 ,因此每走一步都会沿着当前最陡的方向迈出下一步。
标准梯度下降法主要有两个缺点:
训练速度慢 :每走一步都要要计算调整下一步的方向,下山的速度变慢。在应用于大型数据集中,每输入一个样本都要更新一次参数,且每次迭代都要遍历所有的样本 。会使得训练过程及其缓慢,需要花费很长时间才能得到收敛解。容易陷入局部最优解 :由于是在有限的视距内 寻找下山的方向。当落入鞍点(局部最优解),梯度为0,使得模型参数不再继续更新。
0x01 批量梯度下降法(BGD)
从总样本中抽取一个小的批次来计算误差,然后更新模型参数。比如抽取一个大小为n的批次,来进行批量梯度下降,公式即为:
W t + 1 = W t − η t ∑ i = 1 n Δ J ( W t , X ( i ) , Y ( i ) ) W_{t+1}=W_t-\eta_t\sum_{i=1}^n\Delta J(W_t, X_{(i)}, Y_{(i)})
W t + 1 = W t − η t i = 1 ∑ n Δ J ( W t , X ( i ) , Y ( i ) )
其中X ( i ) , Y ( i ) X_{(i)}, Y_{(i)} X ( i ) , Y ( i )
从表达式来看,每次权值调整发生在批量样本输入以后,而不是每输入一个样本就计算一次模型参数,这样就会大大加快计算速度。
0x02 随机梯度下降法(SGD)
就是在批量梯度下降法的基础上,从一批样本中随机选取一个样本X ( i ) , Y ( i ) X_{(i)}, Y_{(i)} X ( i ) , Y ( i )
W t + 1 = W t − η t Δ J ( W t , X ( i ) , Y ( i ) ) W_{t+1}=W_t-\eta_t\Delta J(W_t, X_{(i)}, Y_{(i)})
W t + 1 = W t − η t Δ J ( W t , X ( i ) , Y ( i ) )
随机梯度下降法的过程像是一个盲人下山,不用每走一步计算一次梯度,但是他总能下到山底,只不过过程会显得扭扭曲曲。
SGD的优点就是计算速度快,而且只要不是噪声特别大,SGD均能很好地收敛。缺点是随机选择梯度的过程会引入噪声,使得权值更新的方向不一定正确,此外SGD也没有客服局部最优解的问题。
其中,tf.train.GradientDescentOptimizer()使用随机梯度下降法。
0x03 Δ J ( W ) \Delta J(W) Δ J ( W )
在上述三节中,均有这个东西Δ J ( W ) \Delta J(W) Δ J ( W ) J ( W ) J(W) J ( W )
J = 1 2 n ∑ x ( y − prediction ) 2 prediction = σ ( z ) z = W X + b J=\frac{1}{2n}\sum_x(y-\text{prediction})^2 \\
\text{prediction}=\sigma(z) \\
z=WX+b
J = 2 n 1 x ∑ ( y − prediction ) 2 prediction = σ ( z ) z = W X + b
其关于模型参数的偏导数即为:
∂ J ∂ W = ( y − prediction ) σ ′ ( z ) X prediction = σ ( z ) z = W X + b \frac{\partial J}{\partial W}=(y-\text{prediction})\sigma'(z)X \\
\text{prediction}=\sigma(z) \\
z=WX+b
∂ W ∂ J = ( y − prediction ) σ ′ ( z ) X prediction = σ ( z ) z = W X + b
其中X即为输入数据,也就是通过选择的样本来确定下降的方向和大小。
0x01 动量优化法(Momentum)
0x00 使用动量的随机梯度下降法
使用动量的随机梯度下降法主要是想引入一个积攒历史梯度信息的动量来加速随机梯度下降法的速率。其核心公式为:
v t = α v t − 1 + η t Δ J ( W t , X ( i ) , Y ( i ) ) W t + 1 = W t − v t v_t=\alpha v_{t-1}+\eta_t\Delta J(W_t, X_{(i)}, Y_{(i)}) \\
W_{t+1}=W_t-v_t
v t = α v t − 1 + η t Δ J ( W t , X ( i ) , Y ( i ) ) W t + 1 = W t − v t
其实把1式带入2式,你就会发现其就是在SGD的基础上多了一个α v t − 1 \alpha v_{t-1} α v t − 1 α \alpha α v t v_t v t
由于当前权值的改变会受上一次权值改变的影响,就好比小球在滚动时带上了惯性,加速小球的下滑。
0x01 Nesterov Accelerated Gradient (NAG)
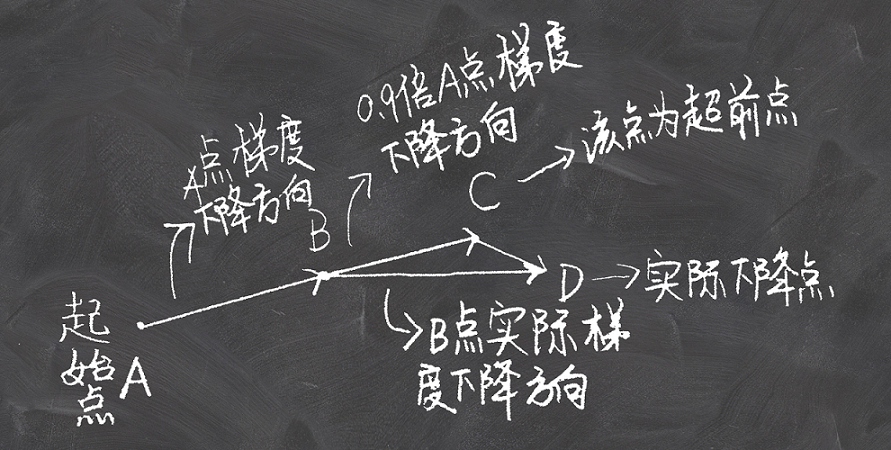
动量法每下降一步都是由前面下降方向的一个累积和当前点的梯度方向组合而成。于是一位大神(Nesterov)就开始思考,既然每一步都要将两个梯度方向(历史梯度、当前梯度)做一个合并再下降,那为什么不先按照历史梯度往前走那么一小步,按照前面一小步位置的“超前梯度”来做梯度合并呢?如此一来,小球就可以先不管三七二十一先往前走一步,在靠前一点的位置看到梯度,然后按照那个位置再来修正这一步的梯度方向。如此一来,有了超前的眼光,小球就会更加“聪明”, 这种方法被命名为Nesterov accelerated gradient简称 NAG。如图:
该法的实际公式如下:
v t = α v t − 1 + η t Δ J ( W t − α v t − 1 ) W t + 1 = W t − v t v_t=\alpha v_{t-1}+\eta_t\Delta J(W_t-\alpha v_{t-1}) \\
W_{t+1}=W_t-v_t
v t = α v t − 1 + η t Δ J ( W t − α v t − 1 ) W t + 1 = W t − v t
W t − α v t − 1 W_t-\alpha v_{t-1} W t − α v t − 1 α = 0.9 \alpha=0.9 α = 0.9
NAG在Tensorflow中与Momentum合并在同一函数tf.train.MomentumOptimizer中,可以通过参数配置启用。
0x02 自适应学习率优化算法
自适应学习率优化算法针对于机器学习模型的学习率,传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。极大忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。
0x00 AdaGrad算法
AdaGrad算法可以独立地适应所有参数模型的学习率,具有代价函数最大梯度的参数相应有个更快速的学习率,具有小梯度的参数在学习率上有较小的下降。其策略可表示为:
W t + 1 = W t − η G t + ϵ Δ J ( W t ) G t = G t − 1 + Δ t J ( W t ) = ∑ t ′ = 1 t Δ t ′ J ( W t ′ ) W_{t+1}=W_t-\frac{\eta}{\sqrt{G_t+\epsilon}}\Delta J(W_t) \\
G_t=G_{t-1}+\Delta_tJ(W_t)=\sum_{t'=1}^{t}\Delta_{t'}J(W_{t'})
W t + 1 = W t − G t + ϵ η Δ J ( W t ) G t = G t − 1 + Δ t J ( W t ) = t ′ = 1 ∑ t Δ t ′ J ( W t ′ )
其中ϵ \epsilon ϵ G t G_t G t G t G_t G t tf.train.AdagradOptimizer。
0x01 RMSProp算法
RMSProp算法修改了AdaGrad的梯度积累为指数加权的移动平均,使得其在非凸设定下效果更好。
W t + 1 = W t − η E [ g 2 ] t + ϵ g t E [ g 2 ] t = α E [ g 2 ] t − 1 + ( 1 − α ) g t 2 g t = Δ J ( W t ) W_{t+1}=W_t-\frac{\eta}{\sqrt{E[g^2]_t+\epsilon}}g_t \\
E[g^2]_t=\alpha E[g^2]_{t-1}+(1-\alpha)g_t^2 \\
g_t=\Delta J(W_t)
W t + 1 = W t − E [ g 2 ] t + ϵ η g t E [ g 2 ] t = α E [ g 2 ] t − 1 + ( 1 − α ) g t 2 g t = Δ J ( W t )
E [ g 2 ] t E[g^2]_t E [ g 2 ] t tf.train.RMSPropOptimizer。
0x02 AdaDelta算法
AdaDelta算法结合了上述的AdaGrad算法和RMSProp算法,且AdaDelta算法不需要设置一个默认的全局学习率。其策略可以描述为:
E [ g 2 ] t = α E [ g 2 ] t − 1 + ( 1 − α ) g t 2 Δ W t = − ∑ i = 1 t − 1 Δ W i E [ g 2 ] t + ϵ W t + 1 = W t + Δ W t E[g^2]_t=\alpha E[g^2]_{t-1}+(1-\alpha)g_t^2 \\
\Delta W_t=-\frac{\sqrt{\sum_{i=1}^{t-1}\Delta W_i}}{\sqrt{E[g^2]_t+\epsilon}} \\
W_{t+1}=W_t+\Delta W_t
E [ g 2 ] t = α E [ g 2 ] t − 1 + ( 1 − α ) g t 2 Δ W t = − E [ g 2 ] t + ϵ ∑ i = 1 t − 1 Δ W i W t + 1 = W t + Δ W t
其中∑ i = 1 t − 1 Δ W i \sum_{i=1}^{t-1}\Delta W_i ∑ i = 1 t − 1 Δ W i
0x03 Adam算法
Adam算法结合了Momentum算法和RMSProp算法,其策略可以表示为:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t , m ^ t = m t 1 − β 1 t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 , v ^ t = v t 1 − β 2 t W t + 1 = W t − η v ^ t + ϵ m ^ t m_t=\beta_1m_{t-1}+(1-\beta_1)g_t,~
\hat{m}_t=\frac{m_t}{1-\beta_1^t} \\
v_t=\beta_2v_{t-1}+(1-\beta_2)g_t^2,~
\hat{v}_t=\frac{v_t}{1-\beta_2^t} \\
W_{t+1}=W_t-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}\hat{m}_t
m t = β 1 m t − 1 + ( 1 − β 1 ) g t , m ^ t = 1 − β 1 t m t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 , v ^ t = 1 − β 2 t v t W t + 1 = W t − v ^ t + ϵ η m ^ t
其中m t m_t m t v t v_t v t β 1 \beta_1 β 1 β 2 \beta_2 β 2 m ^ t \hat{m}_t m ^ t v ^ t \hat{v}_t v ^ t
0x03 结尾
那种优化器最好?该选择哪种优化算法?目前还没能够达达成共识。Schaul et al (2014)展示了许多优化算法在大量学习任务上极具价值的比较。虽然结果表明,具有自适应学习率的优化器表现的很鲁棒,不分伯仲,但是没有哪种算法能够脱颖而出。优化器的选择也取决于使用者对优化器的熟悉程度 (比如参数的调节等等)

 支付宝
支付宝

