树
0x00 二叉树
二叉树(Binary tree)是一个以树型存储的数据结构,每个结点除数据域外都有一个左孩子(left child)以及一个右孩子(right child)。
满二叉树(**perfect **binary tree),除最后一层无任何子节点外,每一层上的所有节点都有两个子结点二叉树。另有定义:一棵高度为,并且含有个节点的二叉树称为满二叉树。此定义与上述定义等价。
完全二叉树(complete binary tree),对于深度为K的有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
我有必要跟你说一下perfect binary tree和full binary tree的区别,如果按照英文字面来理解的话,full binary tree翻译过来应该是满二叉树,其实不然,这样的字面翻译也是错误的,我们需要依据其具体的定义来理解,国外教材是这样定义full binary tree的:
A full binary tree (sometimes referred to as a proper or plane binary tree) is a tree in which every node has either 0 or 2 children.
从上述国外教材的原话中我们可以知道只要满足所有节点不是有0个就是有2个子节点的树就可以称为full binary tree,如下图:
上面这个树在我们国内教材的定义上,不是满二叉树,但其确实对应了国外教材中所述的full binary tree的定义,你可以看到我在满二叉树的定义处指出国内教材中的满二叉树应对应国外教材中的perfect binary tree,来让我们看一下国外教材是怎么定义perfect binary tree的:
A perfect binary tree is a binary tree in which all interior nodes have two children and all leaves have the same depth or same level.
下图即为一个满二叉树,即为perfect binary tree:
此处我们要注意了如果一个二叉树是perfect binary tree那他一定是full binary tree,反之不成立。
在部分国外教材中文译本上,perfect binary tree被翻译为完美二叉树,full binary被翻译为完满二叉树。
下文中所有的满二叉树均指国内教材中有关满二叉树的定义,也就是perfect binary tree。
二叉树常用公式:
- 非空二叉树第层上最多有个结点
- 高度为的二叉树至多有个结点
- 第个结点所在的层次(深度)为
- 具有个结点的完全二叉树的高度为
- 对于任意二叉树,度为0的结点记为,度为2的结点记为,则必有,即度为0的结点总比度为2的结点多一个
- 一棵具有个结点的树,所有结点的度数之和为
- 度为n的结点,第i层最多有个结点
注:
为向下取整符号,结果为不大于x的最大整数,例如
为向上取整符号,结果为不小于x的最小整数,例如
树中一个结点的子结点的个数称为结点的度(degree of node),度大于0的结点称为分支结点(branch node),度等于0的结点称为叶子结点(leaf node)或终端结点(terminal node)。树中结点最大的度数称为树的度。
树的路径长度是从树的根节点到每一个结点的路径长度的总和。
0x01 二叉树的遍历
先看一棵树:
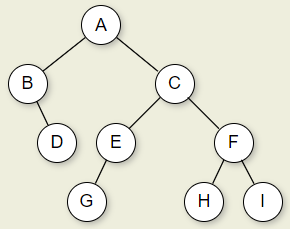
0x00 先序遍历
先序遍历(Preorder Traversal)的遍历过程为先访问根节点,然后递归先序遍历左子树,后递归先序遍历右子树,则对上面的那个树遍历序列应为:
1 | ABDCEGFHI |
我们可以通过LeetCode题目,144. Binary Tree Preorder Traversal来练习树的先序遍历过程,在此题中,不需要你手动建树,他会给你建好一个树然后作为函数的输入参数给你,你只需完成先序遍历的过程,然后输出这个序列即可,给出我写的一个基于递归算法的树的先序遍历的代码:
1 | class Solution { |
0x01 中序遍历
中序遍历(Inorder Traversal)先依次中序遍历左子树,然后访问根节点,最后依次中序遍历右子树,则对上面的那个树中序遍历序列应为:
1 | BDAGECHFI |
同样通过LeetCode题目94. Binary Tree Inorder Traversal来练习树的中序遍历,基于递归算法的代码如下:
1 | class Solution { |
0x02 后序遍历
后序遍历(Postorder Traversal)的遍历顺序为先后序遍历左子树,然后后序遍历右子树,最后后序遍历根节点。则对于上面的那个树后序遍历序列应为:
1 | DBGEHIFCA |
同样通过LeetCode题目145. Binary Tree Postorder Traversal来训练后序遍历的代码,使用递归算法的代码如下:
1 | class Solution { |
不知道细心的你有没有发现,在树的前序遍历、中序遍历以及后序遍历我们所写出来的代码中,不一样的地方只有那个if块里面语句的顺序调换了一下而已。
下面给出一个非递归版的后序遍历实现:
1 | class Solution { |
非递归后序遍历到某个结点时,栈中的序列即为从根节点到此结点的路径
0x03 层序遍历
层序遍历(Level Order Traversal)和上面三种就不一样了,层序遍历基本上就是我们人类肉眼的遍历方法,对于上面图中的那个二叉树,层序遍历顺序为:
1 | ABCDEFGHI |
通过LeetCode题目102. Binary Tree Level Order Traversal来练习层序遍历的过程,注意此题要求你返回一个vector<vector<int>>,输入二叉树的每一层都要单独放在一个vector里面,然后把所有层的vector都打包在一个vector里面返回,使用递归算法实现的代码如下:
1 | class Solution { |
这份代码运行时间4ms击败98.92%的人,但此代码使用了递归算法,基本思路为,我每走到一层记录当前这层所有节点的子节点指针(即为下一层节点指针)放在一个vector里面,然后将其作为参数递归传下去,然后下一次递归的时候即遍历传入的当前一层的指针列表依次记录其中元素的值,然后插入结果集的vector即可。
0x02 二叉树的建立
0x00 什么样的遍历顺序组合可以独一地确立一颗二叉树
二叉树有四种遍历方式,先序遍历、中序遍历、后序遍历以及层序遍历,先给定这四种遍历方式中的任意两个,通过这两个遍历顺序可以唯一的确定一颗二叉树吗?
答案是:当给定中序遍历序列以及剩下的三种任意一个的话,即可唯一地确立一颗二叉树。
如果不给定中序遍历序列,而是给定剩下三种遍历序列的组合的话,是不能唯一地确立二叉树的,看如下示例:
现有二叉树:
1 | 1 |
给定先序遍历序列为12,以及后序遍历序列为21,我们可以看出如下两树均可满足相同的先序及后序遍历序列,所以其不能唯一地确定二叉树:
1 | 1 | 1 |
但如果给定先序遍历序列为12和中序遍历序列21,就能唯一地确定所要求得的二叉树为树1,因为树2的中序遍历序列为12,就能把结点2牢牢地限制住其为1的左孩子。
如果想求得唯一的二叉树,必需有中序遍历序列以及剩下三种遍历序列中的任意一个,如果没有中序遍历序列,剩下的三种遍历序列无论怎么组合,即便三个全部给出也依然无法求得唯一的二叉树。
现在考虑一个问题,假设说我只知道前序或后序遍历序列,则符合此遍历序列的二叉树一共有多少呢?由此可延伸一个相同的问题,个结点可以构成多少种不同的二叉树,此题答案依然为卡特兰数公式:
0x01 通过先序遍历和中序遍历建立二叉树
通过LeetCode题目来练习使用先序遍历和中序遍历建立二叉树的过程,题目链接105. Construct Binary Tree from Preorder and Inorder Traversal,下面的代码使用递归算法完成,效率自然不高:
1 | class Solution { |
大致说一下基本的算法思路,对于上面图中的那个二叉树,其先序遍历序列为:
1 | ABDCEGFHI |
中序遍历序列为:
1 | BDAGECHFI |
先序遍历首先访问的为根节点,由先序遍历的序列可知第一个根节点为A,然后我们在中序遍历里面查找A,因题目已经给出条件You may assume that duplicates do not exist in the tree.说明树中没有重复元素了,所以我们可以直接在中序遍历的序列里查找根节点A所在的位置,依中序遍历规则可知,A前面的元素BD即为A作为根节点时的左孩子,A后面的元素GECHFI即为A作为根节点时的右孩子,然后再向下递归得到以结点B为根节点的子树,依次递归直至先序遍历序列完成一遍时算法结束。
上面的算法,我们每次递归时都会有一个for循环来查找当前根节点在中序遍历序列中的位置,我们可以使用unordered_map将其消除,用空间换时间,在递归之前,我们提前遍历中序遍历序列,将中序遍历的数值作为key和其在vector内的下标作为value,使用unordered_map将其一一对应起来,这样我们可以直接使用二叉树遍历的数值(作为unordered_map的key)来快速找到其在中序遍历序列中的下标(作为unordered_map的value),从而省去了每一次进入使用for循环查找的过程,大大提升了算法的效率,代码如下:
1 | class Solution { |
进行上述优化后,代码的运行时间从20ms缩减到了8ms可见效果还是十分明显的。
0x02 通过中序遍历和后序遍历建立二叉树
通过中序遍历序列和后序遍历序列可以确立一棵唯一的二叉树,我们可以通过LeetCode题目106. Construct Binary Tree from Inorder and Postorder Traversal来练习,基于递归算法的代码如下:
1 | class Solution { |
0x03 线索二叉树
0x00 基本概念
在传统的二叉树的实现中,在一棵树中往往由很多空指针,比如在叶子结点中以及在那些缺少某个孩子的结点中,线索二叉树(Threaded Binary Tree)的实质就是为了把这些空指针全部利用起来,利用这些空的指针域来存放其直接前驱或后继的指针,加快查找结点前驱和后继的速度。线索化的实质就是设法利用二叉树中多余的空指针将二叉树变为一个双向链表。
二叉树为一种逻辑结构,线索二叉树是加上线索后的链表结构,也就是说,它是二叉树在计算机内部的一种存储结构,所以线索二叉树是一种物理结构。
线索二叉树的存储结构:
1 | struct TreeNode { |
其标识域含义如下:
ltag- 0:
left指针指向结点的左孩子 - 1:
left指针指向结点的前驱
- 0:
rtag- 0:
right指针指向结点的右孩子 - 1:
right指针指向结点的后继
- 0:
这里的前驱和后继是相对于构建线索二叉树的遍历序列而言的。
个结点的线索二叉树含有个线索。
在先序线索树、中序线索树和后序线索树三者之中,后序线索树的遍历仍然需要栈的支持,后序线索树在进行遍历时,最后访问根节点,如果从右孩子x返回访问父节点,则此节点的右孩子不一定为空(右指针无法指向其后序遍历的后继),因此后序线索树可能通过指针无法遍历整个二叉树,则需要栈的支持。而先序和中序线索树则不必。由此可延伸一个问题即为,使用后序遍历线索化后的二叉树仍不能有效求解后序后继节点。
0x01 建立中序线索二叉树
如下为基于递归算法的中序线索二叉树的建立,函数的参数为需要线索化的二叉树的根节点,代码如下:
1 | struct TreeNode { |
0x02 建立后序线索二叉树
如下为建立后序线索二叉树的代码,仅变动了中序线索二叉树代码的递归顺序:
1 | // 二叉树结点的存储结构参考建立中序线索二叉树的代码 |
0x04 树、森林与二叉树之间的相互转换
0x00 树转化为二叉树
- 树中所有带有相同双亲的兄弟结点之间加一条连线
- 对树中不是双亲结点的第一个孩子的结点,只保留新添加的该结点与左兄弟结点之间的连线,删去该节点与双亲结点之间的连线
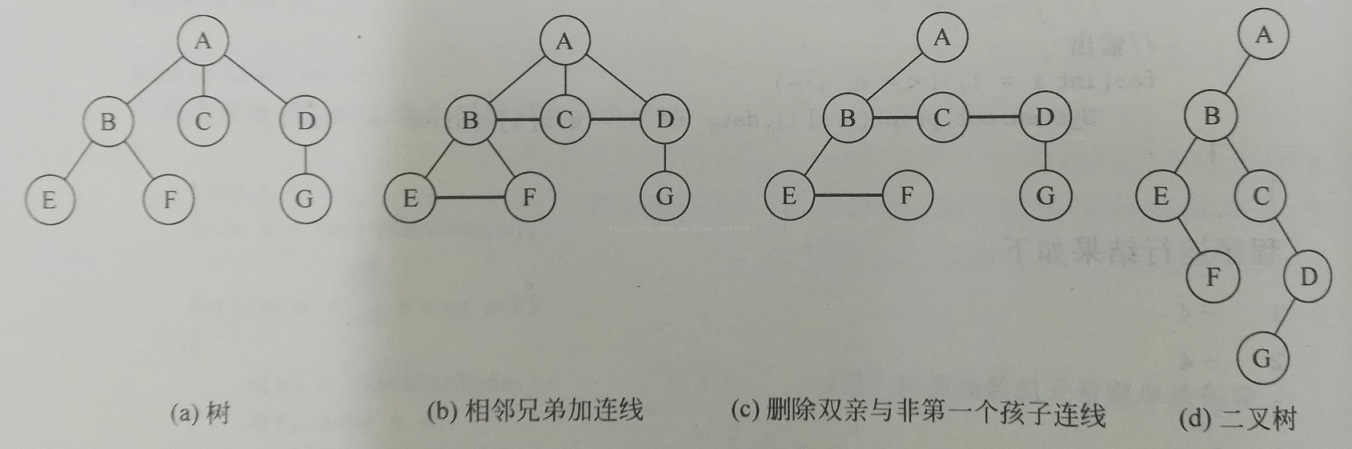
看上图是要注意的一点就是:E和F,在变化之后,F由原来E的兄弟结点变为E的右孩子。
0x01 二叉树转化为树
- 若某结点是其双亲结点的左孩子,则把该结点的右孩子,右孩子的右孩子等等等等都与这些结点的双亲结点连起来
- 删除原二叉树中所有双亲结点与右孩子结点的连线
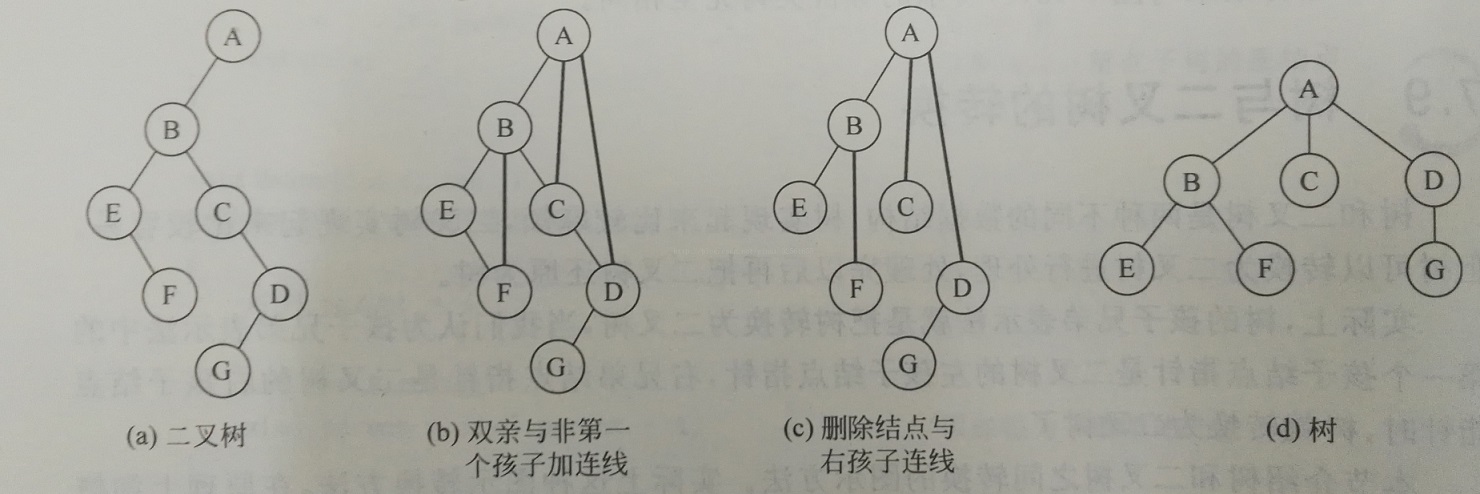
0x02 二叉树转化为森林
如果一颗二叉树有右孩子,那么他可以转换为森林,否则,其只能转化为一棵树。
- 从根节点开始,若右孩子存在,则把与右孩子结点的连线删除
- 再查看分离后的二叉树,若其根节点的右孩子存在,则连线删除
- 循环往复直到所有这些根节点与右孩子的连线都删除为止
- 然后将分离的二叉树全部转化为树
对于根节点来说,去除其右孩子的连线之后,左边的左子树部分就不动了,往下递归也是这个过程只操心右孩子,不再操心其左孩子
高度为的满二叉树转换为森林后所含树的个数一定为。此处要注意二叉树转换成的树或森林是唯一的。
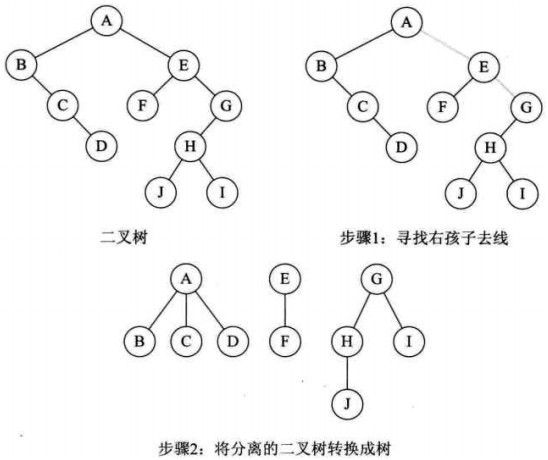
0x03 森林转化为二叉树
- 将森林中的每棵树变为二叉树
- 因为转换所得的二叉树的根结点的右子树均为空,故可将各二叉树的根结点视为兄弟从左至右连在一起,就形成了一棵二叉树
一定是按给定的从左到右的顺序连接
0x05 二叉排序树(又名二叉搜索树或二叉查找树)
二叉排序树,又名二叉搜索树或二叉查找树,在英文里一般将其称为Binary Search Tree,简写为BST,二叉排序树要么为空树,要么具有如下的三大基本特征:
- 若左子树非空,则左子树上所有结点的关键字值均小于根节点的关键字值
- 若右子树非空,则右子树上所有结点的关键字值均大于根节点的关键字值
- 左右子树本身分别也是一颗二叉排序树
因为总有左子树的值<根节点的值<右子树的值,所以对其进行中序遍历总能得到一个递增的有序序列。
二叉排序树理想情况下的高度为:
0x00 二叉排序树的插入
从一道LeetCode题目说起,701. Insert into a Binary Search Tree,此题目要求我们在一颗即成二叉排序树内插入一个元素,使用递归算法,我们可以清晰地得到整个的流程,如下:
1 | class Solution { |
由此可见,新插入的结点一定是叶子结点,如果树中存在相同的元素,那么就将其忽略,如果新插入的元素大于当前结点的值就将其插入到当前结点的右子树中,如果小于就将其插入当前结点的左子树中,递归往复。
递归虽然可以将算法的流程直观地体现出来,但是递归的效率终究不高,上述代码运行时间60ms仅超过了48.11%的人,我们设法将递归消除掉,我一开始惯性思维下写了一个带栈的消除递归的方法,代码如下:
1 | class Solution { |
上面的代码运行时间为44ms,击败了98.93%的人,消除递归确实有效地提升了程序的运行效率,后来我发现那个栈最大长度为1,既然这样我们就可以将那个栈消除掉,代码如下:
1 | class Solution { |
上述的代码运行效率应该和用栈的那个代码差不多才对啊,但是上述代码提交上去之后,运行时间居然为80ms,比递归算法的效率还要差,感觉是其编译器优化出现了问题。
0x01 二叉排序树的删除
二叉排序树删除某个结点时,必须先把被删除结点从存储二叉树的链表中摘下,然后将其左子树和右子树与断开的二叉链表重新连接,并且要保持二叉树的性质不会丢失,可以分三种情况去讨论:
-
如果被删除的结点为叶子结点,那将其直接删除,并不会破坏二叉树的性质
-
如果被删除的结点仅有左子树或者右子树,则让其子树直接代替被删除的结点
-
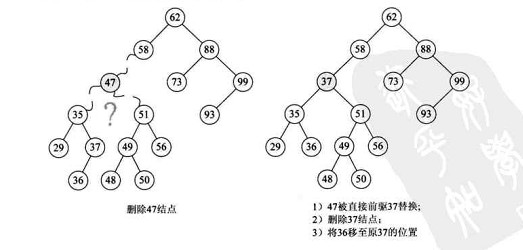
如果被删除的结点同时存在左子树和右子树,用被删除节点的直接前驱或者直接后继来替换当前节点,调整直接前驱或者直接后继的位置,如图:

在上图中,我们要删除47结点,这个结点既有左孩子又有右孩子,我们首先看其中序遍历的序列:
1
29, 35, 36, 37, 47, 48, 49, 50, 51, 56, 58, 62, 73, 88, 93, 99
要删除的结点47的直接前驱为37,所以我们把37拿上去换掉被删除的47,这样就转换成了第一或第二种状况,然后再依第一第二种状况处理即可。
通过LeetCode题目450. Delete Node in a BST来练习上述过程,如果一个结点既有左孩子又有右孩子,此题接受使用其直接前驱或后序两种序列,如下:
1 | root = [5,3,6,2,4,null,7] |
基于递归算法的代码如下:
1 | class Solution { |
此代码运行时间16ms,超过100%的人,在删除时将其分为了三种情况,如果:
- 其同时具有左右孩子,那寻找其中序遍历的直接后继,然后交换当前结点与其直接后继的值,将其进一步转换为下面的两种情况,继续递归
- 其仅具有一个孩子,那就用其仅具有的这个孩子来代替这个结点即可
- 其为叶子结点,直接将其删除,不对二叉排序树的性质产生任何的影响
0x02 二叉排序树的查找
我们先看一道LeetCode题目,700. Search in a Binary Search Tree,此题为简单题,先将其AC掉,然后我们再来分析效率,代码如下:
1 | class Solution { |
对于高度为的二叉排序树,其插入和删除操作的运行时间都是,但在其最坏情况下,当输入序列为一个有序序列时,构造二叉排序树会使得形成的树为一个倾斜的单支树,此时二叉排序树的性能显著变坏,树的高度也增大为输入元素的个数,由此可见,二叉排序树的查找效率取决于树的深度,树的深度越低查找效率越快。如果一棵二叉排序树的形状为仅有左(右)孩子的单支树,其查找的效率和单链表查找的效率就基本一样了。
整体看来,二叉排序树的查找过程和二分查找差不多,而且两者的平均 性能也不相上下,但是二分查找时其判定树是唯一的,二叉排序树则不一定唯一。但是相比较于二分查找有序数组的情况,当插入或删除一个数据时,有序数组的复杂度为,而二叉排序树则无需移动结点,只需移动指针即可完成插入和删除操作,平均的执行时间为,所以在我们选择存储结构时,若当有序表为静态查找表(不会对齐进行频繁的插入删除操作的有序表)时,则适宜使用顺序表作为其存储结构,若有序表时动态查找表,则应选择二叉排序树作为其逻辑结构。
0x03 二叉排序树的判定
如何使用程序来判定一棵给定的树是否为二叉排序树,通过LeetCode题目98. Validate Binary Search Tree来练习,代码如下:
1 | class Solution { |
上述代码的空间复杂度为,占用了额外的空间,我的基本想法是首先求得此二叉树的中序遍历序列,因二叉排序树的中序遍历序列一定是有序的,所以我们可以通过检验此树的中序遍历序列是否有序来判定其是否为二叉排序树。同时编制代码时要注意一点就是,二叉排序树中所有的元素都是独一的,没有重复的。也就是说当输入的二叉树为如下情况时其不为一棵二叉排序树:
1 | 1 |
所以在中序序列判断有序的过程中,还要判断相邻的两个元素是否相同。
下面给出一种空间复杂度为的解决方案:
1 | class Solution { |
这个题的测试用例完美地替我们想到了当输入数据含有INT_MAX的情况,所以我们在设定初始的min和max时要取LONG_MIN和LONG_MAX。
0x06 平衡二叉树
0x00 基本概念
上一节刚刚说过二叉排序树的性能取决于树的高度,树越高,二叉排序树的性能越差,为了避免树的高度增长地过快,降低二叉排序树的性能,而我们要保证树的任意结点的左右子树高度差的绝对值(平衡因子)不超过1,这样的树称为平衡二叉树(Self-balancing binary search tree或Balanced binary tree或AVL)。
注:AVL是最早实现的一种自平衡二叉搜索树,AVL的全称为Adelson-Velskii and Landis,这是以AVL树的三个创始人的名字首字母命名的,就像RSA算法一样。但有些国内的教材上会将平衡二叉树和AVL树放在一起谈,甚至说平衡二叉树就是AVL树,这样的说法是不严谨的,严格来说,AVL树是平衡二叉树的一种。
平衡二叉树要么是空树,要么满足如下的2个特征:
- 其左子树和右子树均为平衡二叉树
- 左子树和右子树高度差的绝对值不超过1
平衡二叉树第h层最少结点数的递推公式:,其中。
0x01 平衡二叉树的判定
下图为一棵平衡二叉树:
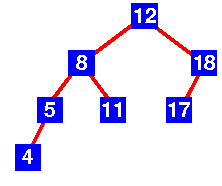
而下图则不是:
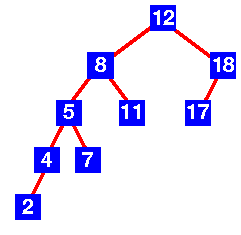
原因是以8为根节点的子树的高度为4,而以18为结点的子树高度为2,两者的高度差为2大于1,所以其不是平衡二叉树。
如下也不是一棵平衡二叉树:
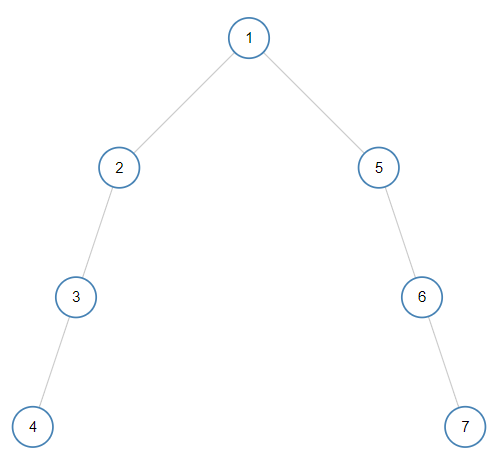
因为结点2的左子树高度为2,右子树高度为0,两者之差的绝对值大于1。
我们可以通过LeetCode题目110. Balanced Binary Tree来练习使用程序来判定一棵给定的二叉树是否为平衡二叉树,代码如下:
1 | class Solution { |
0x02 平衡二叉树的插入
平衡二叉树插入的基本思想是:每次插入一个结点时,都要检查其插入路径上的结点是否因为此次操作而导致不平衡,如果导致了不平衡,则先找到插入路径上离插入结点最近的平衡因子绝对值大于1的结点,再对以此结点为根节点的子树,在保证二叉排序树特性的前提下,调整各节点之间的位置关系,使之重新达到平衡。
步骤如下:
将我们新插入的结点记为w
-
首先按照二叉排序树的插入流程来插入结点w
-
从w开始,向上遍历并找到第一个导致此树不平衡的结点z,将从结点z到结点w路径上的z的孩子记为y,将此路径上的z的孙子结点记为x
-
对以z为根节点的子树进行旋转使整个树重新趋于平衡,有如下4种可能的情况
-
y是z的左孩子且x是y的左孩子,执行LL平衡旋转(右单旋转或Left Left Case),如下 :
1
2
3
4
5
6
7
8T1, T2, T3 and T4 are subtrees.
z y
/ \ / \
y T4 Right Rotate (z) x z
/ \ - - - - - - - - -> / \ / \
x T3 T1 T2 T3 T4
/ \
T1 T2 -
y是z的左孩子且x是y的右孩子,执行LR平衡旋转(先左后右双旋转或Left Right Case),如下 :
1
2
3
4
5
6
7
8
9
10
11
12z z
/ \ / \
y T4 Left Rotate (y) x T4
/ \ - - - - - - - - -> / \
T1 x y T3
/ \ / \
T2 T3 T1 T2
x
/ \
Right Rotate(z) y z
- - - - - - - -> / \ / \
T1 T2 T3 T4 -
y是z的右孩子并且x是y的右孩子,执行RR平衡旋转(左单旋转或Right Right Case),如下:
1
2
3
4
5
6
7z y
/ \ / \
T1 y Left Rotate(z) z x
/ \ - - - - - - - -> / \ / \
T2 x T1 T2 T3 T4
/ \
T3 T4 -
y是z的右孩子并且x是y的左孩子,执行RL平衡旋转(先右后左双旋转或Right Left Case),如下:
1
2
3
4
5
6
7
8
9
10
11
12z z
/ \ / \
T1 y Right Rotate (y) T1 x
/ \ - - - - - - - - -> / \
x T4 T2 y
/ \ / \
T2 T3 T3 T4
x
/ \
Left Rotate(z) z y
- - - - - - - -> / \ / \
T1 T2 T3 T4
-
GeeksforGeeks有一个视频详细讲述了上述的旋转过程,链接如下:
AVL Tree - Insertion | GeeksforGeeks
我们先拿一道LeetCode题目试试手,108. Convert Sorted Array to Binary Search Tree,练习一下平衡二叉树的插入:
1 | class Solution { |
当然这个题自然不是想要你这么做的,我们这么做只是为了练习一下平衡二叉树的插入算法。在此题中,因为其给定的输入序列本身就是一个有序的序列,我们可以用二分法来做,将一个有序的序列转换为平衡二叉树,这个有序序列的中间值一定为所生成的二叉树的根,然后依次往下递归即可,代码如下:
1 | class Solution { |
依相同原理,我们可以完成LeetCode题目109. Convert Sorted List to Binary Search Tree,此题与上题的不同就是其输入的数据结构由数组变成了链表,但其算法的实质还是一样的,在链表中,我们可以使用快慢指针的方法来快速定位链表的中点,代码如下:
1 | class Solution { |
还有一种通过截断链表的方式来进行二分链表的方法,代码如下:
1 | class Solution { |
虽然上述代码相对于我的代码而言具有更高的效率,但是,这样截断链表会造成内存泄露,原因如下:首先传入函数作为参数的ListNode所指向的内存区域需要在driver代码里进行释放(delete),每执行一次函数,这个链表的后半段就被丢掉了,因为slow指针的next域被设置为了nullptr,slow指针此时指向的链表的前半段,链表的后半段就被丢掉了,如此递归直至代码完成,整个链表除去第一个元素之外剩下的元素都没有指针可以直接或间接指向(因为函数执行完成之后第一个结点的next域的值为nullptr),这样在driver代码里进行delete或free操作时,程序只回收了链表第一个结点的内存区域,剩下的全部泄露掉了。这样每测试一组测试数据都会泄露掉(n-1)*sizeof(ListNode)大小的内存,其中n为测试数据所包含结点的个数。
在高并发服务应用中,随着用户流量的增加,内存泄露对应用将会是致命的,内存泄露会导致服务器内存被快速耗尽,内存耗尽时,应用不得不强制终止(业务下线)以避免造成更大的损失(系统失败)。
0x03 平衡二叉树的查找
平衡二叉树的查找与二叉排序树相同,在此前我们分析过二叉排序树的查找效率,发现二叉排序树的查找效率往往取决于树的高度,树越高查找效率越慢,在最坏情况下,也就是其为单支树的情况下,其查找效率与单向链表查找效率相同。平衡二叉树左右子树的高度相差不会超过1,所以自然不会出现单支树的情况,所以平衡二叉树的平均查找长度为,其中为结点数。
0x07 B树和B+树
0x00 B树基本概念
B树(B-tree)又称为多路平衡查找树,B树中所有结点的孩子结点数的最大值称为B数的阶(order),通常用m表示,一棵m阶B树(B tree of order m或m-order B tree)通常具有如下性质:
- 树中每个结点至多有m棵子树,即至多有m-1个关键字
- 若根节点不是终端结点,则至少含有2棵子树
- 除根节点外的所有非叶节点至少有棵子树,即至少含有个关键字
- 结点中关键字的个数n符合关系$\lceil \frac{m}{2} \rceil-1 \leqslant n \leqslant m-1 $
- 所有叶结点都出现在同一层次上,并且不带信息(这些结点实际上是不存在的,指向这些结点的指针为空)
如下图,这是一个5阶B树:
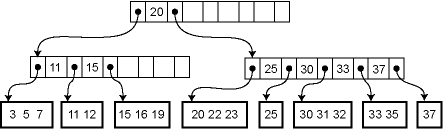
此图是我从Cornell大学数据结构公开课的讲义上弄下来的,很形象地描绘出了B树以及其每一个结点的构造,我们拿他的一个顶点来稍加分析,如下:
其中数字代表了当前结点的关键字,而且满足从左往右依次递增。
左右两边的*号为指向其子树树根的指针,而且数字左边的指针所指向的子树中的关键字均小于当前数字,数字右边的指针所指向的子树中的关键字均大于等于当前数字。
有的实现版本中,每个结点最左边还有一个数字,用来代表当前结点中关键字的个数。
再看下图,这是一个4阶B树:
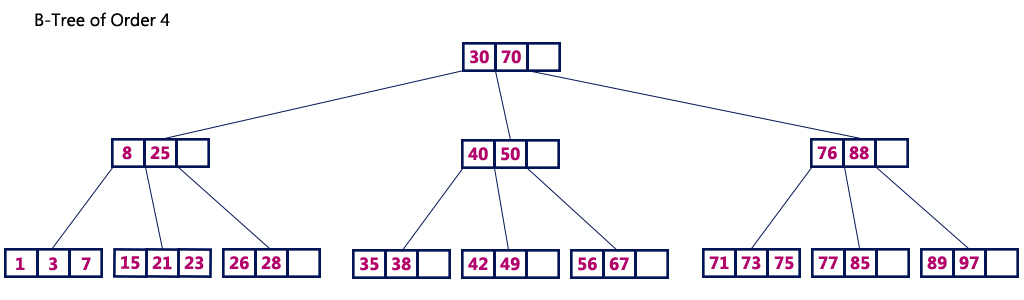
因为你看他有一个孩子结点时[15, 21, 23],这个结点包含了3个关键字,自然在未来,这个结点最多就会有4个孩子,所以其为一棵4阶B树。
0x01 B树的高度
B树中的大部分操作所需要的磁盘存取次数与B树的高度成正比。
对于一棵包含n个关键字,高度为h,阶数为m的B树:
- 关键字的个数n应满足,高度h则有
- 若让每个结点中关键字的个数达到最少,此时,容纳相同多元素的B树的高度可达到最大,由B树的定义,第一层至少有1个顶点,第二层至少有2个顶点,此后除根节点外的每个非终端结点至少有棵子树,则第三层至少有个结点,以此类推,第h+1层(叶子结点层)至少有个结点。
- 则B树的高度范围为
0x02 B树的查找
B树的查找类似于二叉排序树的查找,只不过是每个结点变成了有多个关键字的有序表,所以每个结点上所做的并不像二叉排序树一样是两路分支决定,而是多路分支决定。故其查找过程包含两个基本操作
- 首先在B树中找结点
- 然后在结点中找关键字
B树往往被存储在磁盘中,故前一个操作往往在磁盘中进行,当找到目标结点时,先将结点中的信息读入内存,然后采用顺序查找法或二分查找查找等于目标值的关键字。如果查找到叶节点(没有存放任何信息的结点)则说明查找失败。
还是看这个图:
假设我们要查找56,则首先从树根开始,56介于30-70之间,所以下一步查找中间的那个子树,此后,56大于50,然后查找50右边的那棵子树,继而在子树的结点中找到56。
0x03 B树的插入
将关键字K插入B树的流程如下:
- 定位:利用B树的查找算法,找出插入该关键字的最底层中某个非叶结点
- 插入:在B树中,每个非失败结点的关键字的个数都在区间内,当插入后的结点关键字个树仍在上述区间内(小于m),那么可以直接插入,否则,必需对结点进行分裂:
- 取一个新结点,将插入K后的原结点从中间位置将其中的关键字分为两部分
- 左半部分保持在原结点中
- 右半部分包含的关键字放入新结点中
- 中间位置的结点()插入原结点的父节点中
- 若此时父节点的关键字个数也超过了上限,则继续执行上述的分裂操作,直到这个过程传递到根节点,导致B树的高度加一(注意看下图insert(7)的过程)
下面这个图就很形象了:
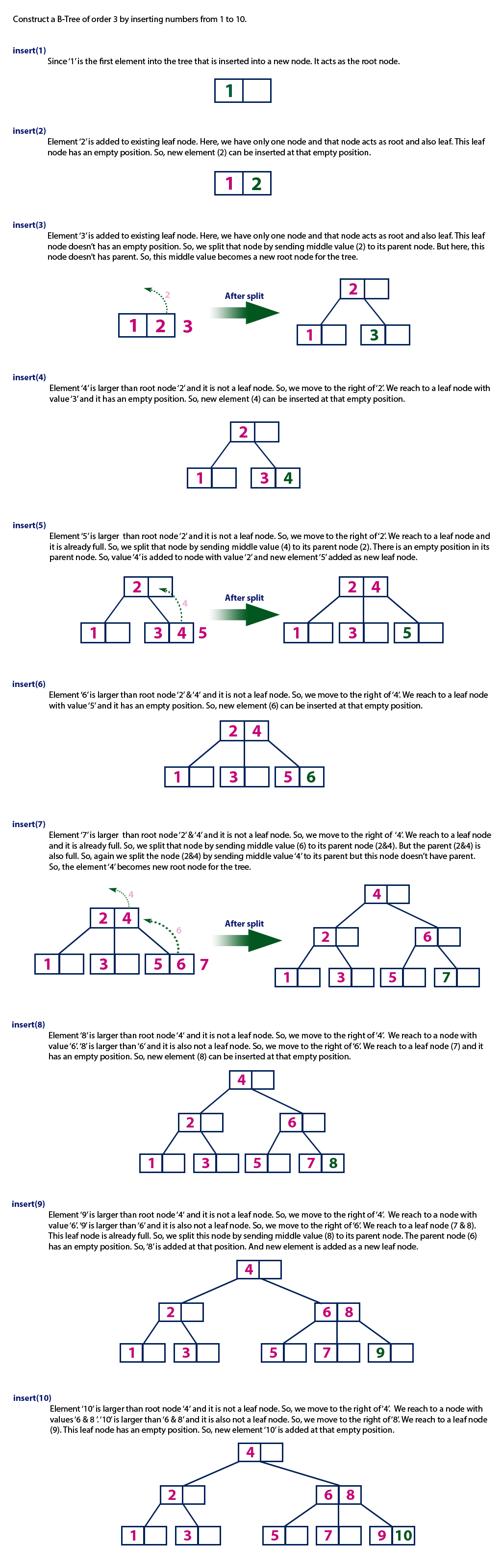
上图中,插入结点1, 2, 4, 6, 8时为直接插入,插入结点3, 5, 7时为需要分裂后插入。注意插入结点3和7的过程导致B树的高度增加。
注意:
B树中插入关键字一定是插入在最底层的某个非叶结点内。
0x04 B树的删除
B树的删除操作类似于插入操作,同样需保证删除之后的结点中的关键字个数大于等于,因此涉及到合并问题。B树的删除有如下几种情况:
当被删除的结点在终端结点时,有如下情况:
- 当被删除的关键字所在的结点的关键字个数大于,那么删除之后的树,仍然满足B树的定义,所以可以直接将其删除,如下图中删除D的过程。
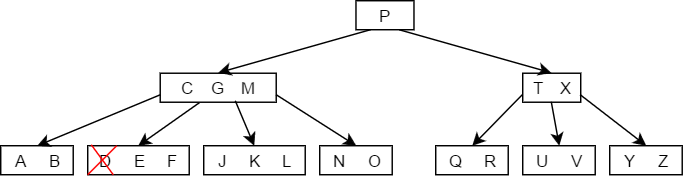
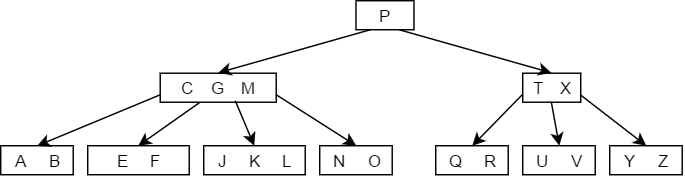
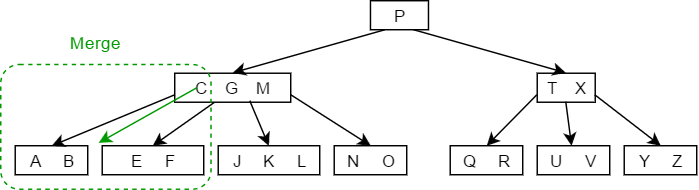
- 当被删除的关键字所在结点删除前关键字个数恰好等于,且与此相邻的右(左)兄弟结点的关键字个数大于等于,此时兄弟够借,则需要调整该节点右(左)兄弟结点以及其双亲结点,也就是从旁边借一个节点过来调整以达到新的平衡,如下图中删除关键字F:
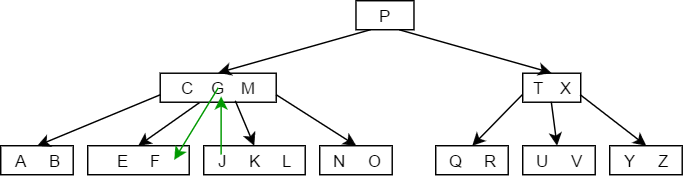
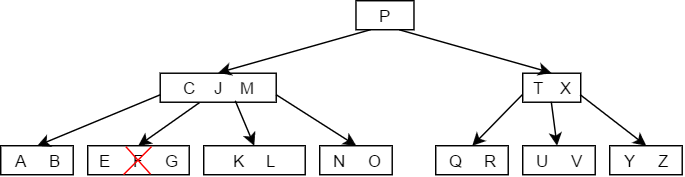
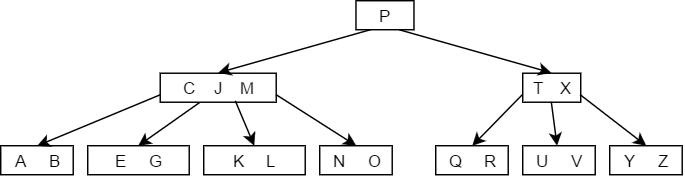
- 当被删除的关键字所在结点删除前关键字个数恰好等于,且此时与此结点相邻的左右兄弟结点的关键字个数也等于,此时左右兄弟不够借了,那么就需要将关键字删除后与右(左)兄弟结点及双亲结点中的关键字进行合并,如下图删除关键字B的过程:
在合并的过程中,双亲结点中的关键字个数会减少,若其双亲结点时根节点并且关键字个数减少至0,则直接将根节点删除,合并后的新结点成为根,如果双亲结点不是根节点,且关键字的个数减少至,那么又要与它自己的兄弟结点进行调整或合并操作,直到符合B树的要求为止。
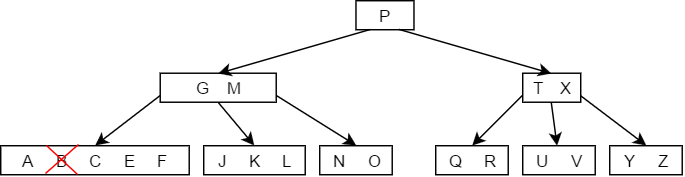
当被删除的结点不在终端结点时,假定被删除的关键字为K,有如下情况:
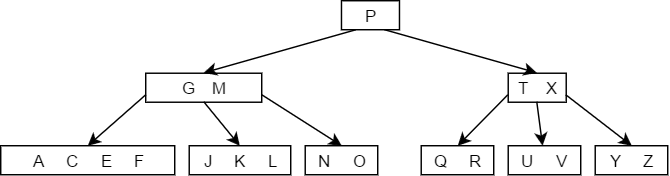
- 如果小于K的子树中关键字的个数大于,那么直接用K的前驱值来代替K即可,如下图删除结点M的过程:
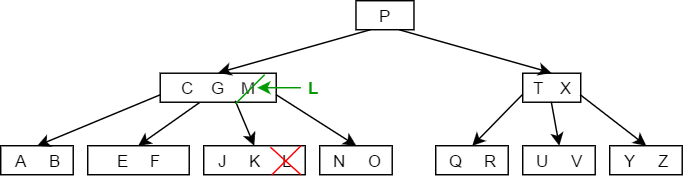
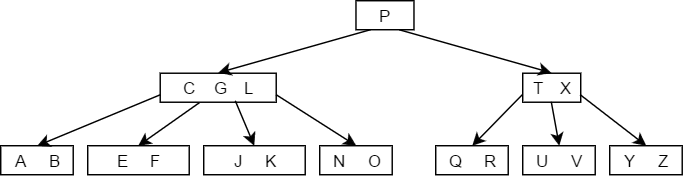
- 如果大于K的子树中关键字的个数大于,则找出K的后继值,用其后继值来代替K,如下图中删除结点G的过程:
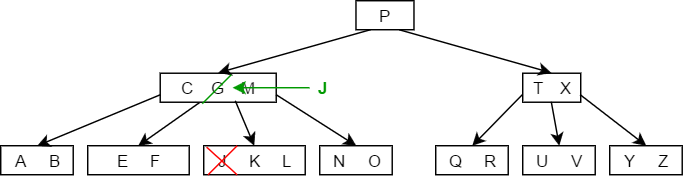
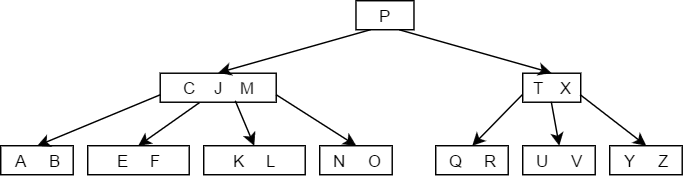
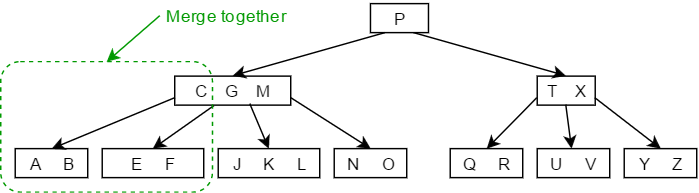
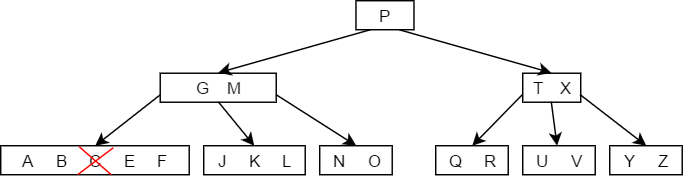
- 如果K的左右两个子树的结点个数均为,则直接将两个子节点合并,并直接将K删除即可,如下图中删除结点C的过程:
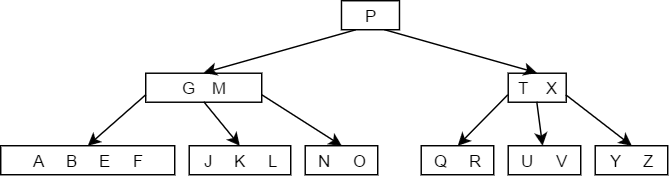
0x05 B+树的基本概念
B+树(英文念B plus tree)是广泛出现在数据库文件索引中的一种B树的变形树。一棵m阶B+树需满足如下条件:
- 每个分支结点最多有m棵子树(子结点)
- 非叶根节点至少有2棵子树,其他每个分支结点最少有棵子树
- 结点的子树个数与关键字个数相等
- 所有叶结点包含全部关键字及指向相应记录的指针,而且叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序互相用指针链接起来。
- 所有分支结点中仅包含它的各个子结点中关键字的最大值及指向其子结点的指针
如图是一棵3阶B+树:
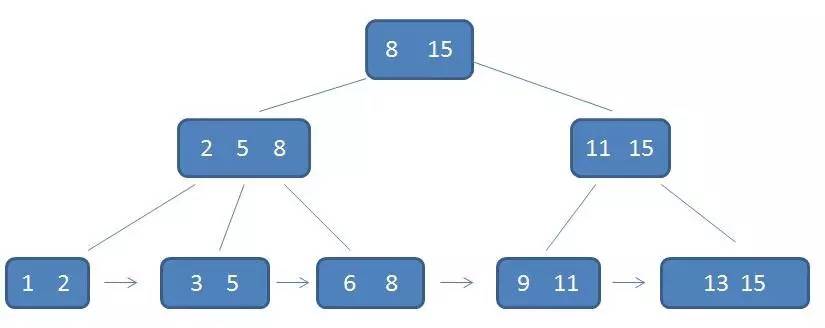
m阶B树与B+树的不同:
| B+树 | B树 | |
|---|---|---|
| 具有N个关键字的结点所含有的子树个数 | ||
| 每个非根内部结点关键字个数N的范围 | ||
| 根节点关键字个数N的范围 |
- 在B+树中,叶结点包含信息,所有非叶结点仅起到索引作用,非叶结点中每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址。
- B+树中,叶节点包含了全部的关键字,非叶结点中出现的关键字也全部会出现在叶节点中,而在B树中,叶结点包含的关键字和其他结点包含的关键字是不重复的。
B+树的增删改查与B树基本类似,可以对B+树进行从最小关键字开始的顺序查找和从根节点进行的多路查找两种查找策略,而且在查找过程中,如果非叶结点上的关键字的值等于查找的给定值时,查找并不终止,而是继续查找,直到找到叶节点上的该关键字为止。所以不管成功与否,B+树的查找路径都是一条从根节点到叶节点的路径。
0x08 哈夫曼树
0x00 基本概念
哈夫曼树(Huffman tree)又被称为最优二叉树,它是一种带权路径长度最短的树。何谓权值(Weight)呢,实际上就是树中结点数据域所存放的数值,只不过这组数值在一些特定的算法和实际应用中是具有实际意义的,所以我们将其称为该结点的权值。从树的根节点到任意结点的路径长度(经过的边数)与该结点上的权值的乘积称为该结点的带权路径长度。树中所有结点的带权路径长度之和称为该树的带权路径长度(Weighted Path Length),即为:
式中是第个结点所带的权值,是该节点到根节点的路径长度
上述中所提到的权值的应用,在这里举一个例子出来,方便大家理解权值到底是做什么用的,在英文中,字母e的出现几率最高,而z的出现几率则最低。当利用霍夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节,即8个比特。二者相比,e使用了一般编码的的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
具有n个叶子结点的哈夫曼树,非叶子结点的的总数为:n-1
0x01 哈夫曼树的构造
具体可参考秒懂百科下的这个视频,可谓是非常直观了:怎么画出哈夫曼树
0x02 哈夫曼编码
对一个待处理的字符串序列,如果对每个字符都使用等长度的二进制位来表示,则这称为固定长度编码。如果对不同的字符用不等长的二进制位来表示,则这即为可变长度编码(Variable-length code)。在实际应用中,我们可以依据各个字符出现的频率,对频率高的字符赋以短编码,对频率低的字符赋以长编码,从而使字符平均编码长度缩短,起到压缩数据的效果。哈夫曼编码即为一种有效的数据压缩编码。如果没有一个编码是另一个编码的前缀,则这样的编码称为前缀编码。例如编码0、101、100即为前缀编码,因为其没有一个码是其他码的前缀,所以对于一个输入序列我们可以唯一地分析出原码,例如00101100可唯一地分析出0, 0, 101, 100。
0x09 二叉树的高度和宽度
0x00 求二叉树的最大高度
我们可以使用如下LeetCode题目来练习求二叉树的最大高度,104. Maximum Depth of Binary Tree,基于递归算法的代码如下:
1 | class Solution { |
0x01 求二叉树的最小高度
从一道LeetCode题目练起,111. Minimum Depth of Binary Tree,此题预寻求一棵给定二叉树的最小高度,最小高度换句话说就是从根节点出发到任一叶子结点的最短距离,例如给定如下的二叉树:
1 | 3 |
其最小高度应为2,也就是从根节点3到叶子结点9的距离,此题代码如下:
1 | class Solution { |
0x02 求二叉树的最大宽度
做了一道LeetCode题目662. Maximum Width of Binary Tree,此题要求你找出二叉树最长的那一行的长度,而且所求的长度不仅包括有效节点的长度,而且还要将有效节点之间为null的那些元素也算进去,例如:
1 | Input: |
我一开始写了如下的代码:
1 | class Solution { |
上面的代码,在第104/108组测试用例中超内存,第104组测试用例相当的大,最长的宽度有178535个结点(输出结果)。然后就导致Memory Limit Exceeded,很伤心。
- 支付宝
- 微信


