0x00 导言
传统的图像检索往往分为两个步骤,第一步即提取图像的全局特征 并在搜索引擎中进行搜索,第二步即对检索出图像的局部特征 采用空间验证等手段对进行重排序并返回。本文提出了一种新的特征算法,有效融合了局部特征及全局特征,仅一步就可返回最佳结果。
0x01 背景知识
0x00 GeM池化
对于一张K × h × w K\times h\times w K × h × w K K K X \mathcal{X} X
f ( g ) = [ f 1 ( g ) ⋯ f k ( g ) ⋯ f K ( g ) ] where f k ( g ) = ( 1 ∣ X k ∣ ∑ x ∈ X k x p k ) 1 p k , ∣ X k ∣ = h × w \text{f}^{(g)}=[\text{f}^{(g)}_1 \cdots\text{f}^{(g)}_k\cdots\text{f}^{(g)}_K] \\
\text{where }\text{f}^{(g)}_k=(\frac{1}{|\mathcal{X}_k|}\sum_{x\in \mathcal{X}_k}x^{p_k})^{\frac{1}{p_k}},~ |\mathcal{X}_k|=h\times w
f ( g ) = [ f 1 ( g ) ⋯ f k ( g ) ⋯ f K ( g ) ] where f k ( g ) = ( ∣ X k ∣ 1 x ∈ X k ∑ x p k ) p k 1 , ∣ X k ∣ = h × w
当p k = 1 p_k=1 p k = 1 p k → ∞ p_k\rightarrow \infty p k → ∞
let u = lim p k → ∞ ( 1 ∣ X k ∣ ∑ x ∈ X k x p k ) 1 p k ln u = lim p k → ∞ 1 p k ln ( 1 ∣ X k ∣ ∑ x ∈ X k x p k ) ⩽ lim p k → ∞ 1 p k ln ( x max p k ) ⩽ ln ( x max ) ∴ lim p k → ∞ ( 1 ∣ X k ∣ ∑ x ∈ X k x p k ) 1 p k ⩽ x max \text{let }u=\lim_{p_k\rightarrow\infty}\left(\frac{1}{|\mathcal{X}_k|}\sum_{x\in \mathcal{X}_k}x^{p_k}\right)^{\frac{1}{p_k}}\\
\begin{align*}
\ln u &=\lim_{p_k\rightarrow\infty}\frac{1}{p_k}\ln\left(\frac{1}{|\mathcal{X}_k|}\sum_{x\in \mathcal{X}_k}x^{p_k}\right)
\\
&\leqslant \lim_{p_k\rightarrow\infty}\frac{1}{p_k}\ln\left(x_{\max}^{p_k}\right)\\
&\leqslant\ln (x_{\max})
\end{align*}\\
\therefore \lim_{p_k\rightarrow\infty}\left(\frac{1}{|\mathcal{X}_k|}\sum_{x\in \mathcal{X}_k}x^{p_k}\right)^{\frac{1}{p_k}}\leqslant x_{\max}
let u = p k → ∞ lim ( ∣ X k ∣ 1 x ∈ X k ∑ x p k ) p k 1 ln u = p k → ∞ lim p k 1 ln ( ∣ X k ∣ 1 x ∈ X k ∑ x p k ) ⩽ p k → ∞ lim p k 1 ln ( x m a x p k ) ⩽ ln ( x m a x ) ∴ p k → ∞ lim ( ∣ X k ∣ 1 x ∈ X k ∑ x p k ) p k 1 ⩽ x m a x
同时,还可以用其所在的神经网络来学习p k p_k p k
0x01 空洞卷积
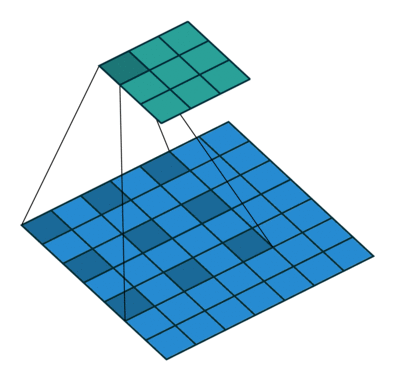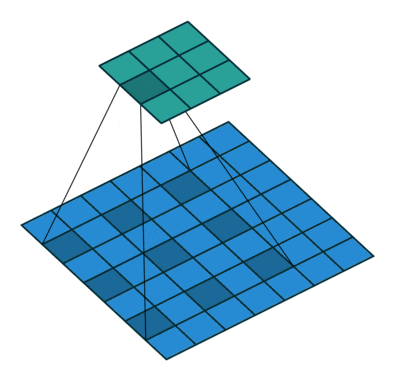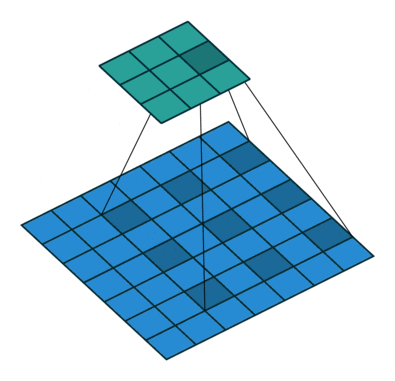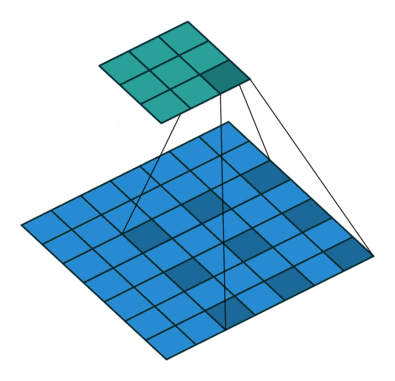
空洞卷积就是在标准的卷积核里面加入空洞,以此来增加感受野。同时引入了一个新的参数dilation rate表示kernel的间隔数量。因为kernel本身也算一个,所以一个正常的卷积核的dilation rate为1。如下即为一个3 × 3 3\times3 3 × 3
其卷积流程:
0x02 Batch Normalization
在网络的训练过程中,每一次参数迭代更新后,上一层的输出数据经过这一层网络计算后,数据的分布可能就会发生变化,为下一层网络的学习带来困难(神经网络本来就是要学习数据的分布,要是分布一直在变,学习就很难了)。这就是所谓的internal covariate shift问题。Batch Normalization的作用则是将数据重新拉回到均值为0方差为1的正态分布上,一方面使得数据分布一致,另一方面避免梯度消失、梯度爆炸。其基本公式如下:
y = x − m e a n ( x ) V a r ( x ) + e p s γ + β y=\frac{x-mean(x)}{\sqrt{Var(x)}+eps}\gamma+\beta
y = Va r ( x ) + e p s x − m e an ( x ) γ + β
其中,Var和mean分别代表方差和均值,eps则是为了防止分母变为0所加的一个稳定系数,一般为1e-5。γ \gamma γ β \beta β
0x02 方法论
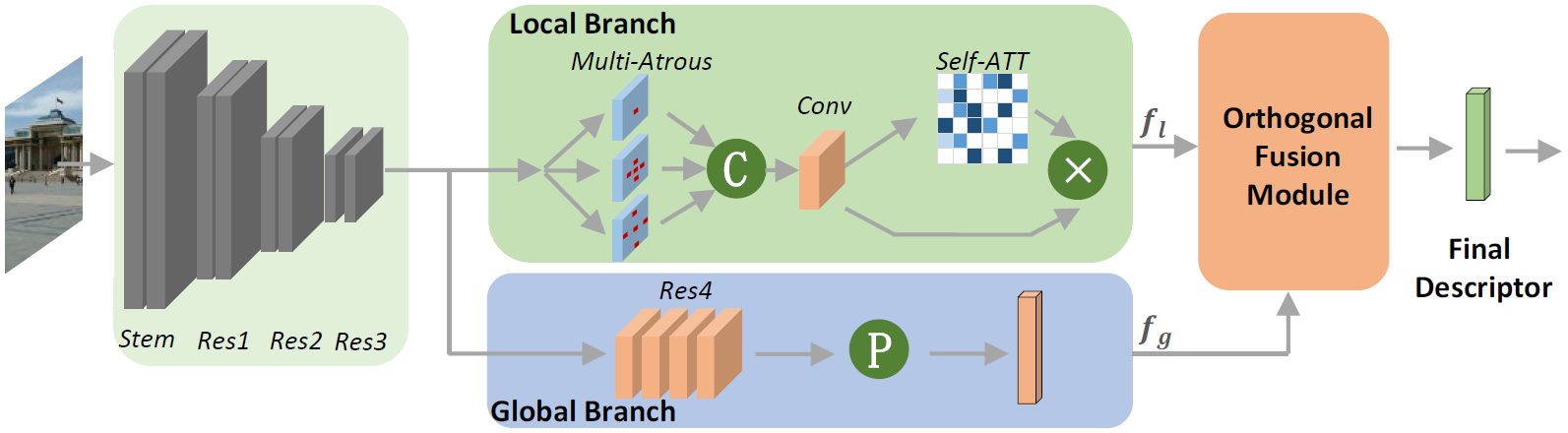
整体流程如下所示:
首先,输入图像会被经过一个残差网络,在通过第三个残差层Res3之后,其输出将会分别通过一个局部特征提取分支(Local Branch)和一个全局特征提取分支(Global Branch)。
对于全局特征提取分支而言,后面的流程还是继续ResNet,只不过在上面做了一点小改进:其一,结尾的均值池化被改为了GeM池化;其二,结尾的池化过程完成后,将通过一个全连接层用于全局特征的降维。
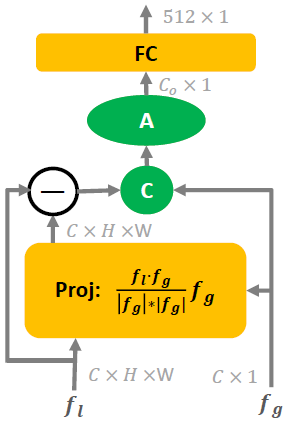
对于局部特征的提取分支而言,就比较复杂了,详细的流程可以看下图:
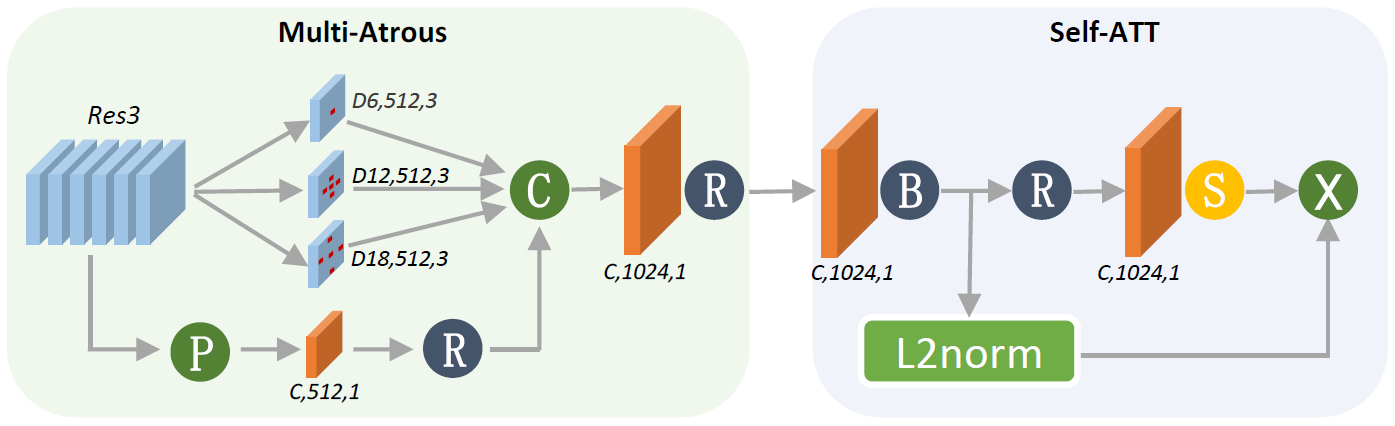
首先Res3的输出会通过一个Atrous Spatial Pyramid Pooling(ASPP)模型,这个模型同样组合了两个分支。上面的一个分支由3个空洞卷积(Dilated/Atrous Convolution)核组成,目的是模拟图像金字塔,使特征保证一定程度的尺度不变性。下面的则是一个全局平均池化分支。二者所产生的特征会被直接拼接成一个特征矩阵,然后通过一个1 × 1 1\times 1 1 × 1
ASPP的输出特征将会注入到自注意力模型(self-attention module)中来确定特征图中的关键点并输出。该模型会对每一个特征点返回一个注意力分数,将这个注意力分数与L2归一化后的特征相乘计算出来的最终结果则为该图像的局部特征。
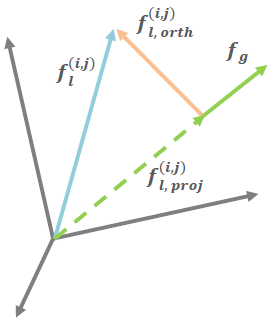
对于局部特征f l f_l f l f g f_g f g
对于一个局部特征点f l ( i , j ) f_l^{(i,j)} f l ( i , j ) f g f_g f g f l , p r o j ( i , j ) f_{l,proj}^{(i,j)} f l , p ro j ( i , j ) f l , o r t h ( i , j ) f_{l,orth}^{(i,j)} f l , or t h ( i , j ) f l ( i , j ) − f l , p r o j ( i , j ) f_l^{(i,j)}-f_{l,proj}^{(i,j)} f l ( i , j ) − f l , p ro j ( i , j )
其中投影f l , p r o j ( i , j ) f_{l,proj}^{(i,j)} f l , p ro j ( i , j )
f l , p r o j ( i , j ) = f l ( i , j ) ⋅ f g ∣ f g ∣ 2 f g f_{l,proj}^{(i,j)}=\frac{f_l^{(i,j)}\cdot f_g}{|f_g|^2}f_g
f l , p ro j ( i , j ) = ∣ f g ∣ 2 f l ( i , j ) ⋅ f g f g
其中:
f l ( i , j ) ⋅ f g = ∑ c = 1 C f l , c ( i , j ) f g , c ∣ f g ∣ 2 = ∑ c = 1 C ( f g , c ) 2 f_l^{(i,j)}\cdot f_g=\sum_{c=1}^Cf_{l,c}^{(i,j)}f_{g,c}\\
|f_g|^2=\sum_{c=1}^C(f_{g,c})^2
f l ( i , j ) ⋅ f g = c = 1 ∑ C f l , c ( i , j ) f g , c ∣ f g ∣ 2 = c = 1 ∑ C ( f g , c ) 2
假设我们传入一个C × H × W C\times H\times W C × H × W f l f_l f l C × 1 C\times1 C × 1 f g f_g f g f o r t h f_{orth} f or t h C × H × W C\times H\times W C × H × W C × 1 C\times 1 C × 1 f g f_g f g 512 × 1 512\times 1 512 × 1
神经网络的训练过程还是类似于图像分类任务,假设目标数据集将图像分为了N N N W ^ ∈ R 512 × N \hat{\mathcal{W}}\in R^{512\times N} W ^ ∈ R 512 × N
L = − log ( exp ( γ × A F ( ω ^ t T f g ^ , 1 ) ) ∑ n exp ( γ × A F ( ω ^ n T f g ^ , y n ) ) ) L=-\log\left(\frac{\exp\left(\gamma\times AF\left(\hat\omega_t^T\hat{f_g},1\right)\right)}{\sum_n\exp\left(\gamma\times AF\left(\hat\omega_n^T\hat{f_g},y_n\right)\right)}\right)
L = − log ∑ n exp ( γ × A F ( ω ^ n T f g ^ , y n ) ) exp ( γ × A F ( ω ^ t T f g ^ , 1 ) )
其中,f g ^ \hat{f_g} f g ^ w i ^ \hat{\mathcal{w}_i} w i ^ W ^ \hat{\mathcal{W}} W ^ f g ^ \hat{f_g} f g ^ W ^ \hat{\mathcal{W}} W ^ w i ^ f g ^ \hat{\mathcal{w}_i}\hat{f_g} w i ^ f g ^
A F ( s , c ) = { cos ( arccos ( s ) + m ) , if c = 1 s , if c = 0 AF(s,c)=\left\{
\begin{array}{ccl}
\cos(\arccos(s)+m),& \text{if } c=1\\
s,& \text{if } c=0
\end{array}
\right.
A F ( s , c ) = { cos ( arccos ( s ) + m ) , s , if c = 1 if c = 0
其中,s表示余弦相似度,m表示ArcFace margin,是一个超参数,默认取值0.15,c=1表示当前为ground truth。
0x03 实践论
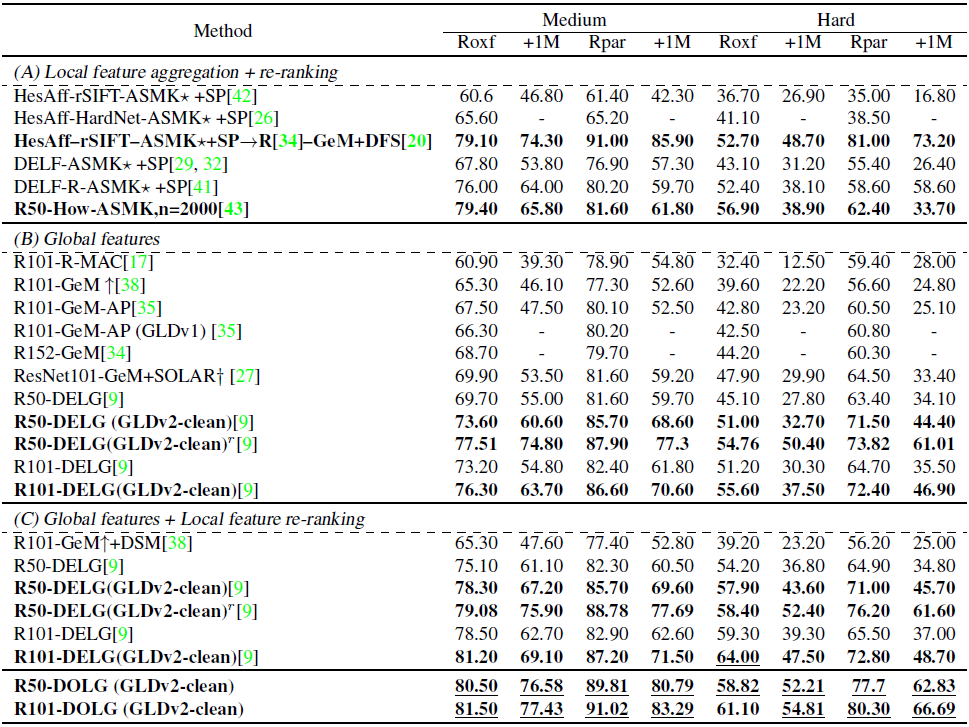
对于神经网络的训练,作者使用的是Google Landmark数据集在19年clean过之后的版本,GLDv2-clean,其中包含1580470张图片,共分为81313类。对于检索性能的测试,作者用的revise过后的Oxford5k和Paris6K数据集,以mAP作为评估指标进行的测试。整体的实验结果如下表所示:
作者把此前的state-of-the-art分为了三类,A类为单纯使用局部特征+重排序,B类为仅使用全局特征,C类为使用全局特征和局部特征的融合特征并进行重排序。本文中所提出来的算法应该归属于C类,其主要竞争对手也是C类。
作者在进行对比的过程中发现,如果仅使用全局特征进行检索的话,结果里面将会出现很多false positive的结果,这可能是由于两张图像语义相似导致的。通过重排序,可以有效地减少false positive的数量,但是对于局部特征仍然相似的false positive图像来说,没用。
0x04 讨论
作者在本文中的一些设定仅仅是为了验证这种神经网络设计方案及特征正交融合策略的有效性,并不旨在探索更为细致的调优方案。
 支付宝
支付宝

